
Écrire un article est le meilleur moyen que j’ai trouvé pour m’approprier un sujet. Cela me force tout simplement à prendre le temps nécessaire pour m’y intéresser et me former. C’est la méthode que j’ai appliquée avec Tribes pour des sujets de scale, de management, de prise de parole, d’analyse financière, etc.
Cet article est donc avant tout un exercice personnel pour mieux comprendre ce que Partoo construit aujourd’hui et souhaite construire demain en s’appuyant sur l’IA. Par la suite j’ai écris de nombreux article plus approfondis sur différents sujets liés à l’intelligence artificielle, que ce soit le RLHF, le RAG et les agents virtuels, les paramètres des prompts ou encore la performance des modèles.
J’ai décidé de structurer cet article en trois parties :
- La première partie consiste à présenter les concepts de base de l’IA
- La deuxième à creuser le sujet de la génération de texte
- La troisième à expliquer plus en détails son application concrète chez Partoo
Ce sujet étant très technique, j’espère que vous ne me tiendrez pas rigueur de certaines erreurs ou approximations : je reste d’ailleurs très preneur de feedback et d’analyses complémentaires.
PS : Si vous souhaitez tester notre le Partoo, il vous suffit de vous rendre sur notre site web et de cliquer sur la bulle en bas à droite :
Les 4 niveaux d’analyse d’une rupture technologique
La majorité des contenus qui existent en ligne sur l’Intelligence Artificielle porte sur ses implications, qu’elles soient sociétales, économiques ou même philosophiques. C’est la manière dont la majorité d’entre nous a découvert l’IA, par la presse ou des amis : “cette rupture technologique va changer le monde !”
Si j’ai beaucoup entendu parler de l’IA ces dernières années, j’ai notamment été piqué de curiosité après avoir écouté un épisode de Génération Do It Yourself dans lequel intervenait Laurent Alexandre, fondateur de Doctissimo et spécialiste de l’IA. Avec une opinion tranchée et des airs de gourou, Laurent Alexandre cherche souvent à choquer par la forme comme par le fond. Pour lui, l’IA est avant tout synonyme d’hypercroissance : “à long terme, la croissance va augmenter. Il va y avoir plus d’activité économique. Les fantasmes de décroissance, de baisse du pouvoir d’achat, c’est terminé”.
Son analyse porte sur un choc de productivité, un choc technologique et même une fracture profonde entre ceux qui savent et ceux qui ne savent pas : “On parle d’un choc de même nature qu’auraient eu les gens sous Napoléon 1er, à l’époque où il y avait encore 29 000 porteurs d’eau à Paris, si on leur avait dit que 250 ans plus tard on aurait des Youtubers, des chirurgiens cardiaques, des fabricants de microprocesseurs ou des astronautes”.
Pourtant, après 2h30 d’écoute, je suis resté sur ma faim. Quand on parle de ce genre de révolutions technologiques, il y a quatre niveaux d’analyse selon moi :
- les implications à long terme,
- les applications concrètes,
- la maîtrise de la technologie en elle-même,
- et la compréhension de son fonctionnement
Anticiper les implications à long terme c’est se livrer aux analyses les plus faramineuses, mais aussi les plus captivantes car elles laissent court à l’imagination ; elles permettent les hypothèses les plus folles. C’est tout le fond de commerce de Laurent Alexandre : “l’IA va entraîner un boom de plein de nouveaux métiers, de nouvelles activités, de nouvelles sciences, de nouveaux business models, de nouveaux types d’entreprises qui vont générer des besoins énormes (…).
Nous ne rentrons donc pas dans une zone de mort du travail, de remplacement du travail par l’IA. Nous rentrons dans un monde d’hypercroissance, d’hyper-technologie où les opportunités vont être absolument extraordinaires.”
Si ce sujet vous passionne, je vous conseille la lecture de son livre, La Guerre des Intelligences à l’ère de chat GPT (en parallèle de Start to Scale !)

Mais si on redescend un peu sur terre, un deuxième niveau d’analyse doit vite être apporté : celui des applications concrètes de cette technologie. C’est ce niveau d’analyse qui m’a le plus déçu dans le web3, lorsque j’ai cherché à lister ses applications dans mon quotidien perso ou pro. Mais lorsque l’on y réfléchit, le nombre d’applications concrètes de l’IA est phénoménal : on peut gagner en productivité grâce à ChatGPT, retrouver de l’IA dans ses outils du quotidien (Gmail, Notion…) et quand on est une startup tech comme Partoo, on peut même l’intégrer à ses propres produits. C’est d’ailleurs de cette manière que j’ai commencé à m’y intéresser plus en détail : en échangeant avec les équipes produit de Partoo sur ce sujet et en étudiant les cas d’usages pour nos clients. Et pas besoin de travailler dans une startup tech pour découvrir les applications de l’IA dans notre quotidien : il suffit maintenant d’aller sur le site de Carrefour ou de Castorama.
Mais lister les applications d’une technologie ne permet pas de faire la différence en tant qu’individu, de vraiment “prendre le virage” de l’IA. Le niveau 3 d’analyse est donc celui de la maîtrise : comment maîtriser ces outils, comment prompter, comment bien utiliser l’IA en intégrant ses codes et ressorts ? Pour cela, un seul moyen, la pratique. Il suffit d’ouvrir son navigateur pour utiliser les différentes versions de ChatGPT (la dernière en date étant la 4), de prompter, de générer des images, et de s’entraîner. Mais ce n’est pas suffisant pour s’approprier un sujet.
Lorsqu’il s’agit de découvrir un nouveau domaine, j’aime beaucoup la métaphore de la guitare que m’a un jour partagé Thibault Levi-Martin, mon associé chez Partoo.
Pour apprendre à jouer de la guitare, il y a souvent deux extrêmes. Celui qui va directement prendre la guitare dans ses mains et se mettre à jouer quelques accords : il s’entraîne alors sans relâche, souvent par plaisir ou pour impressionner ses amis. Sans forcément connaître les notes, les accords ou le solfège. Et il y a le théoricien, qui va ouvrir un livre, et apprendre toute la théorie sans jamais toucher la guitare. Il connaîtra tout, comprendra tout mais ne maitrisera pas l’outil. Ça marche aussi avec la photographie, l’IA ou encore avec le management ! Comme vous l’aurez peut-être anticipé, la bonne approche repose sur un juste milieu entre ces deux manières de faire, entre la pratique et la théorie.
Après la maîtrise, qui est le 3ème niveau d’analyse de l’IA, vient donc la compréhension théorique. Et pour mieux comprendre comment fonctionne l’IA, j’ai décidé d’écrire un article qui résumerait tout ce que j’en ai compris pour le moment. En espérant que cela puisse servir à d’autres !
IAcadémie par Tribes
A noter que depuis la rédaction de cet article, j’ai continué à me former jusqu’à regarder une petite centaine d’heures de formations… que j’ai décidé de résumer dans une série de 4 webinars d’une heure chacun : l’IAcadémie à retrouver sur Youtube en cliquant sur ce lien ou en regardant le premier ci-dessous.
L’objectif est de couvrir un maximum de sujet avec une vision d’ensemble… en français et de manière accessible !
Sujets à la pelle : GANs, LLM, NLP, Computer Vision, GPUs, IAG, entrainement, Fondation Model, Cloud Computing, fine-tuning, RLHF, Agents IA, RAG, biais, régulation, Multi-agent modeling…
–
–
1) Qu’est ce que l’IA : rappel des bases
L’intelligence artificielle (IA) est un domaine de recherche multidisciplinaire de l’informatique qui vise à créer des machines capables d’effectuer des tâches nécessitant historiquement une intelligence humaine. Une machine est donc considérée comme étant “intelligente” lorsqu’elle imite le comportement cognitif humain pour accomplir des tâches qui nécessitent de l’intelligence.
Ces tâches incluent, entre autres, la prise de décision, la reconnaissance de formes, la compréhension du langage naturel, la perception sensorielle ou la résolution de problèmes complexes.
Le Machine Learning
Une des premières disciplines de l’IA est le Machine Learning (Apprentissage Automatique) qui se concentre sur la construction de systèmes capables d’apprendre à partir de données. Plutôt que d’être explicitement programmés pour accomplir une tâche particulière, ces systèmes sont entraînés en utilisant de grandes quantités de données et des algorithmes qui leur donnent la capacité d’améliorer leurs performances avec le temps. Le machine learning englobe ainsi une grande variété de techniques, y compris la régression, la classification, le clustering, et bien d’autres.
Pour s’entraîner, ces algorithmes nécessitent donc des données qui peuvent être étiquetées (la “réponse” ou le “résultat” est connue) ou non étiquetées. Une fois formé sur des données, l’algorithme crée un “modèle” qui peut être utilisé pour faire des prédictions ou prendre des décisions sans être explicitement programmé pour le faire.
L’entraînement est le processus d’ajustement du modèle qui permet à l’algorithme “d’apprendre” en ajustant ses paramètres pour minimiser son erreur. Une fois le modèle formé, il peut être utilisé pour faire des prédictions sur de nouvelles données.
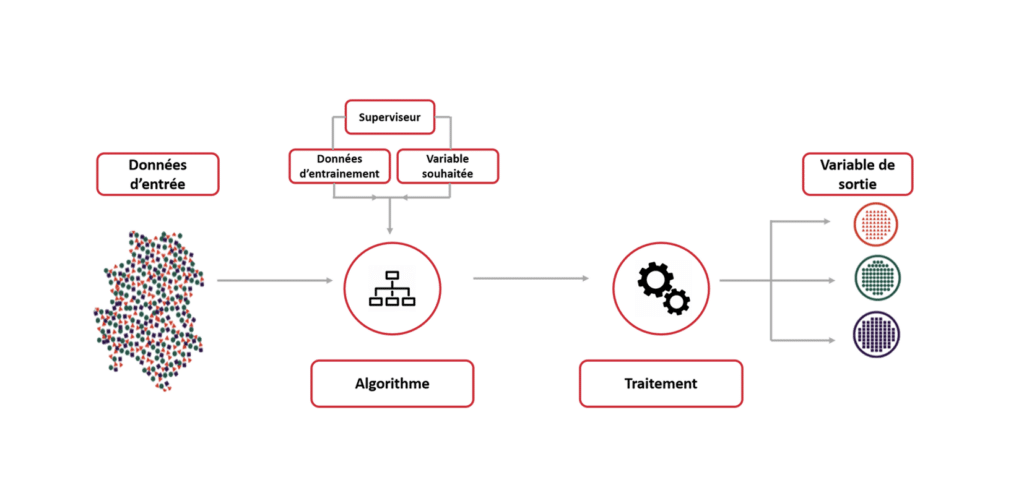
Il existe d’ailleurs plusieurs types d’apprentissage automatique, notamment :
a) L’apprentissage Supervisé
Les algorithmes sont formés sur un ensemble de données “étiquetées” où le “résultat” est déjà connu. L’objectif est de faire des prédictions ou des classifications. Par exemple, prévoir le prix d’une maison en fonction de ses caractéristiques (surface, DPE, localisation, etc). A noter que dans cet exemple les technologies de Machine Learning viennent compléter les algorithmes de régression plus “classiques” qui ont du mal à traiter des objectifs multiples avec des variables interdépendantes.
b) L’apprentissage Non Supervisé
Les algorithmes sont formés sur des données sans étiquettes préétablies, cherchant à identifier des structures ou des patterns : on parle de clustering c’est-à-dire cette capacité à créer des groupes (clusters) au sein d’un ensemble de données. Si on veut par exemple regrouper les avis des clients de Partoo sous la forme de thèmes cohérents (relation client, propreté, prix…), il peut être intéressant d’utiliser un apprentissage Non Supervisé. Sans qu’on lui fournisse des thèmes en amont, le modèle va ainsi identifier les avis qui ont des thèmes similaires et les classer ensemble.
c) L’apprentissage par Renforcement
Dans ce type d’apprentissage, l’algorithme apprend en interagissant avec un environnement et en recevant des feedbacks sous forme de récompenses ou de punitions pour ses actions. Nous en reparlerons plus tard pour le cas spécifique des LLM.
Le machine learning est utilisé dans de nombreux domaines allant de la recommandation de produits en ligne, à la détection de fraudes bancaires, en passant par la reconnaissance vocale et bien d’autres applications.
Le deep learning ou apprentissage profond
Le “deep learning” est un sous-ensemble du machine learning qui se concentre sur l’utilisation de réseaux neuronaux à plusieurs couches, appelés “réseaux neuronaux profonds”. Ces réseaux sont inspirés par la structure du cerveau humain, bien qu’ils en soient des modèles très simplifiés. Le deep learning a révolutionné de nombreux domaines de l’IA, en particulier la reconnaissance d’images, la reconnaissance vocale, la traduction automatique.
C’est sans doute le sujet de l’IA que j’ai le plus de mal à comprendre. La suite de cet article sera peut-être plus simple, accrochez-vous !
Les réseaux neuronaux profonds sont des modèles composés de nombreuses couches de neurones. Plus un réseau est “profond” (c’est-à-dire qu’il a de nombreuses couches), plus il peut représenter des fonctions complexes. A noter que l’entraînement des modèles profonds nécessite souvent une puissance de calcul importante, généralement fournie par des unités de traitement graphique (GPU) ou des unités de traitement tensoriel (TPU) – termes que vous avez peut-être déjà entendus, car ils déterminent la puissance de calcul disponible pour un modèle.
Le deep learning a considérablement fait progresser les capacités de l’IA ces dernières années, mais il reste un ensemble d’outils parmi d’autres dans la boîte à outils du machine learning – chaque outil ayant ses propres forces et faiblesses en fonction de la tâche à accomplir.
Les domaines de l’Intelligence Artificielle
L’intelligence humaine est par nature protéiforme : elle s’applique aux textes, aux images, à la vidéo, aux sons, aux déplacements, etc. Il en va de même pour l’IA. Il peut donc être utile ici de rappeler les différentes formes d’Intelligences artificielles pour en comprendre l’étendue.
Un des domaines d’IA les plus populaires est sans doute le traitement du langage naturel (NLP), qui est à la base de ChatGPT. Ce sera le focus du prochain chapitre.
Si vous êtes clients de Partoo et que vous cherchez à analyser des interactions clients, vous avez peut-être déjà entendu parler des techniques de “Sentiment Analysis”. Elles font référence à l’utilisation de techniques de traitement du langage naturel (NLP), de statistiques et de machine learning pour identifier et extraire les émotions subjectives à partir de textes. L’objectif est alors de déterminer l’attitude de l’auteur vis-à-vis d’un sujet particulier ou l’émotion globale d’un texte. C’est un des cas d’usage que nous avons testé dès 2020 chez Partoo pour analyser les millions d’avis Google Maps de nos clients.
Tout un domaine de l’IA concerne aussi la robotique (robots autonomes ou interactifs) ou encore la logistique – avec des algorithmes qui permettent aux algorithmes de trouver un chemin optimal ou planifier des tâches pour atteindre un objectif.
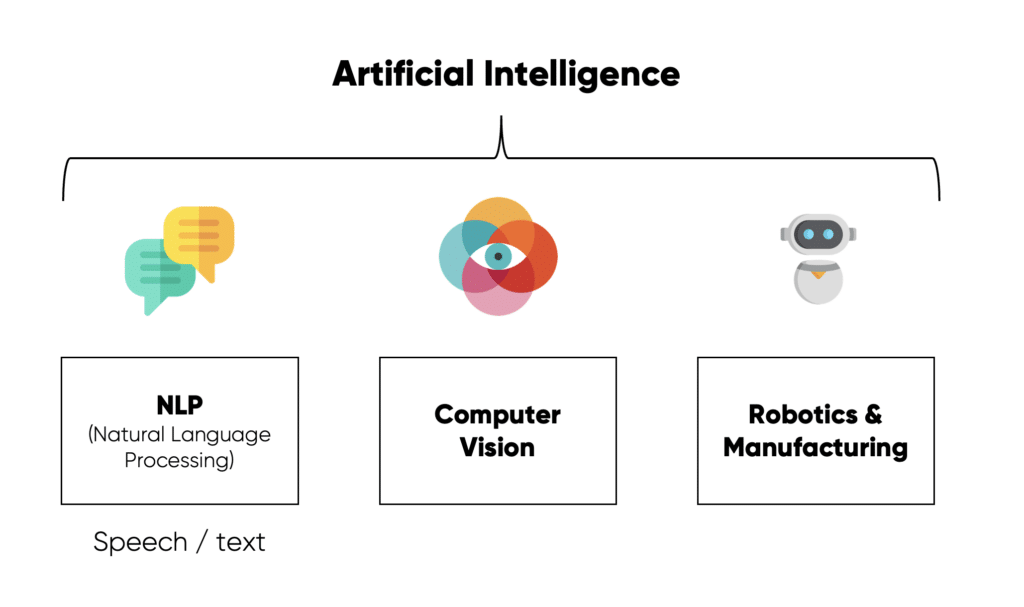
La “computer vision” est un autre domaine de l’intelligence artificielle et de l’informatique qui vise à donner aux machines la capacité de “voir” et d’interpréter visuellement le monde qui les entoure. Elle cherche à reproduire certaines des fonctions du système visuel humain et à en tirer des informations utiles à partir d’images ou de vidéos. Parmi ses capacités clés, il y a par exemple la reconnaissance d’objets, la détection de visages, la reconnaissance de formes, la segmentation d’images (par exemple, retirer un arrière-plan), la reconnaissance de gestes, le traitement d’images, la reconstruction 3D…
A noter que Partoo a commencé à investir dans l’IA dès 2017 sur ce type de technologie. Nos premiers cas d’usage ont consisté en du machine learning appliqué à de la reconnaissance d’image par Computer Vision. Pendant 2 ans, Antoine Nuttinck a mis à profit ses compétences en deep learning pour tenter de résoudre nos enjeux d’IA. Une des problématiques sur lesquelles il a le plus travaillé a notamment été la géolocalisation précise de centaines de milliers de points de vente, clients de Partoo – pour des enseignes comme Carrefour ou Leroy Merlin. En effet, une problématique que nous avions à l’époque était la faible qualité des coordonnés GPS fournis par nos clients pour référencer leurs points de vente sur des cartes (à partir des adresses postales de chaque magasin). Vous avez peut-être pu en faire l’expérience sur Google Maps lorsqu’un point de vente est mal positionné sur la carte.
Pour répondre à ce problème, l’algorithme de Machine Learning que nous avons développé était capable d’identifier les logos de nos clients, dans l’objectif de les reconnaître dans Google Street View et ainsi définir précisément la coordonnées GPS de chaque point de vente. Cet algorithme fonctionnait d’ailleurs par apprentissage supervisé : nous annotations les logos à la main pour permettre ensuite à l’algorithme de les reconnaître. On voit d’ailleurs ici qu’il faut bien distinguer les méthodes utilisées – ici du Machine Learning par apprentissage supervisé – et les typologies de contenus analysés – ici des images (Computer Vision).

L’IA générative
Si les modèles de Machine Learning permettent d’analyser des contenus, de les traiter, de les segmenter ou d’émettre des prédictions, la mise à disposition de l’IA générative au grand public via Chat GPT a transformé notre perception de l’IA.
En effet, contrairement aux autres domaines de l’intelligence artificielle, l’IA Générative, comme son nom l’indique, concerne la génération de nouvelles données.
Les modèles génératifs cherchent ainsi à produire de nouveaux contenus (comme des images, des textes, de la musique, etc.) qui, bien que similaires aux contenus d’entraînement, sont des créations inédites et originales en soi. Des techniques comme les GANs (réseaux antagonistes génératifs) et les VAEs (auto-encodeurs variationnels) sont populaires dans ce domaine – pour ceux qui souhaitent creuser le sujet 😉
Ainsi, même si l’IA Générative utilise également des techniques de machine learning pour fonctionner, on peut de manière très simplifiée, opposer les deux domaines :
- Le Machine Learning permet d’ANALYSER (ex. reconnaissance d’image, clustering de texte, prédiction…)
- L’IA Générative permet de CRÉER (ex. génération d’image avec DALL-E et Midjourney ou de texte avec ChatGPT 4, Google Bard, Notion AI…)
L’avènement de l’IA générative ouvre donc de nouvelles perspectives et de nouvelles applications pour les entreprises, en particulier grâce aux technologies NLP (traitement du langage) et des LLM (Large Language Model) qui seront le sujet du prochain chapitre.

L’IA générale, l’AGI
Il est cependant difficile de terminer ce chapitre sur l’introduction à l’Intelligence artificielle sans évoquer l’AGI ou “Artificial General Intelligence” (Intelligence Artificielle Générale en français).
Ce concept dont vous avez peut-être déjà entendu parler dans la presse grand public fait référence à un type d’intelligence artificielle qui possèderait la capacité de comprendre, d’apprendre et d’appliquer ses connaissances dans n’importe quel domaine, à un niveau équivalent ou supérieur à l’intelligence humaine. Autrement dit, une AGI serait capable d’accomplir n’importe quelle tâche intellectuelle qu’un être humain peut réaliser.
Voici quelques éléments clés concernant l’AGI :
- Polyvalence : Contrairement à l’IA “étroite” (ou spécialisée) qui est conçue pour une tâche spécifique (comme jouer aux échecs, reconnaître des images, ou traduire des langues), l’AGI serait capable de s’adapter et d’apprendre une variété de tâches sans être spécifiquement pré-programmée pour celles-ci.
- Apprentissage autonome : Une AGI serait capable d’apprendre de manière autonome à partir de données brutes sans nécessiter une intervention humaine spécifique ou des données étiquetées.
- Raisonnement : Elle pourrait raisonner, planifier, résoudre des problèmes complexes, penser de manière abstraite, et même posséder une conscience de soi (selon certaines définitions).
- Interactions avancées : L’AGI pourrait comprendre le langage naturel humain, interagir de manière sophistiquée avec son environnement et même comprendre et simuler des émotions.
Il est ici important de rappeler que l’AGI reste largement théorique et est un objectif non atteint à ce jour. C’est ce niveau d’Intelligence Artificielle qui est la source de tous les fantasmes et de toutes les peurs liés à l’IA. Mais si beaucoup parlent de science-fiction, l’avènement de l’AGI est une évidence pour beaucoup de spécialistes.
Pour remettre une pièce dans la machine, je me permets de remettre ci-dessous un passage du podcast de Génération Do It Yourself de Stéphane Polu (fondateur de Dust et ancien employé d’Open AI). A noter qu’une grande partie des idées de cet article est directement tirée de cet épisode à écouter absolument.
“Il y a des équipes entières chez Open AI qui sont dédiées à la “sûreté” et ce qu’on appelle l’alignement des modèles. L’objectif c’est de faire en sorte que le modèle suive les préférences humaines et essaye de ne pas tous nous tuer une fois qu’il sera potentiellement plus intelligent que nous. C’est un problème qui est extrêmement difficile puisque dès qu’on essaye de réfléchir à un système en face de nous qui est potentiellement plus intelligent que nous, il est difficile de l’aligner car il risque de trouver la parade.
Il y a toujours un risque que l’AGI arrive en “fast take-off”, c’est-à-dire du jour au lendemain (vs. un “slow take-off”) mais si on essaye de pousser le raisonnement, dans un scénario de fast take-off, je pense que l’humanité a quand même le contrôle car si cette intelligence émerge un jour, elle sera probablement très gourmande en énergie : quoi qu’il arrive, worst case scenario, on coupe le courant. Mais on peut imaginer des scénarios ou au bout d’un certain temps, ce ne serait plus possible ! (…) La réalité c’est qu’il y a encore beaucoup de barrières à franchir avant d’en arriver là.”
2) Comprendre le NLP et les LLM
Après avoir traité des concepts génériques, l’objectif de ce chapitre est de se focaliser sur un domaine spécifique de l’IA, à savoir l’IA générative ; et un domaine spécifique de l’IA générative, à savoir la génération de texte sur la base des technologies NLP.
Pour commencer à appréhender comment fonctionne l’IA générative utilisée par des technologies comme ChatGPT, il est important de comprendre les bases des technologies NLP – acronyme de Natural Language Processing, ou Traitement Naturel du Langage en français. A noter qu’il existe d’autres acronymes associés à NLP comme NLU (Natural Language Understanding) ou TALN (Traitement Automatique du Langage Naturel).
Les technologies NLP peuvent aider sur de nombreuses tâches comme la traduction, l’analyse de sentiment, la classification, l’extraction d’information, les résumés de textes et la génération de texte. C’est aussi sur la base de technologies de NLP que Partoo a développé son dernier cas d’usage par IA, à savoir la suggestion de réponses aux avis en ligne par intelligence artificielle – qui sera plus précisément le sujet du 3ème chapitre de cet article.
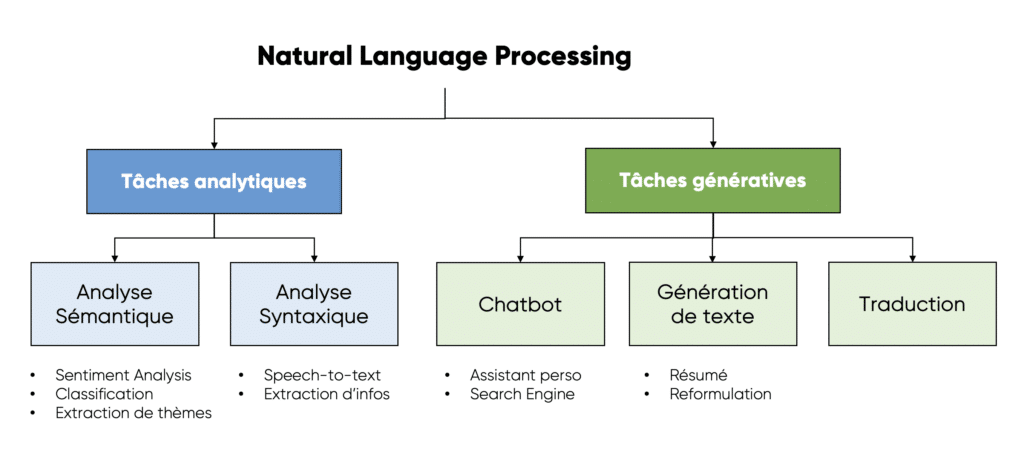
A noter que la séparation analyse / génération est très simplificatrice car pour générer une réponse, il faut dans un premier temps analyser la question
Comment l’IA interprète t’elle les mots ?
Il est tout d’abord intéressant de se pencher sur la manière dont les algorithmes conçoivent les “mots” : c’est un des aspects de l’IA qui m’a le plus interpellé. Pour comprendre cette partie, il peut être utile de revenir à ses cours de mathématiques de fin d’études sur les vecteurs et les espaces multi-dimensionnels. Pour faire simple, les mots peuvent être représentés sous forme de vecteurs numériques afin que les “machines” puissent les traiter : cela permet de simplifier leur compréhension, leur analyse et surtout leur stockage.
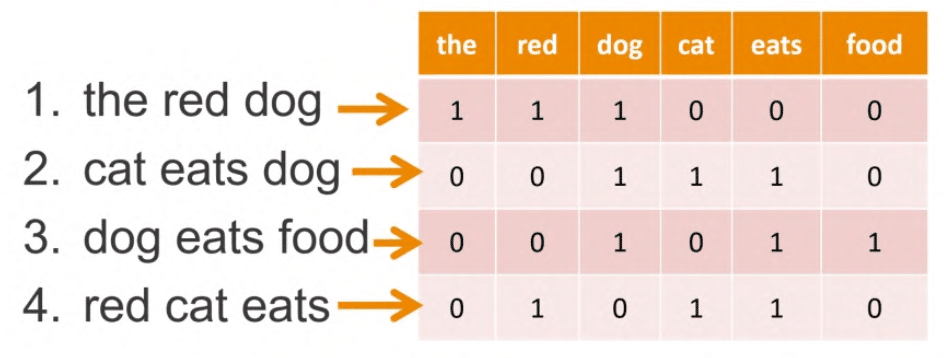
La “tokénisation” consiste ainsi à délimiter les éléments constituants d’un texte, et ainsi à associer des tokens à des mots – ou plus tard à des syllabes comme dans ChatGPT. La “vectorisation”, c’est-à-dire la transformation de mots et textes en données numériques, permet ensuite d’associer à une phrase un ensemble de tokens. Jusqu’en 2013, les méthodes de Machine Learning (“Bag of Words” ou TF-IDF) permettent alors d’identifier des thèmes au sein de certains textes en les vectorisant et en simplifiant leur contenu : retrait des majuscules et des mots courants (“stop words”), racinisation (simplification d’un mot à sa racine) et abstraction de l’ordre des mots dans la phrase. On peut alors segmenter tous les textes qui parlent des mêmes sujets : par exemples ceux qui parlent de chats (cats) dans l’exemple ci-dessous :
Mais en 2013, Google (Word2Vec) popularise une nouvelle manière de vectoriser les mots qui va révolutionner les techniques de NLP : le “word embeddings”.
Au départ, chaque mot est associé à un vecteur aléatoire : c’est l’initialisation. En utilisant de grands corpus de texte (le contexte), le modèle apprend alors à ajuster ces vecteurs de manière à ce que les mots qui apparaissent dans des contextes similaires aient des vecteurs proches. Par exemple, “roi” et “reine” sont souvent utilisés dans des contextes similaires et auront donc des vecteurs proches. Mais on peut prendre des exemples plus complexes : le mot “mouton” sera proche de “cheval” mais sera aussi proche de “bouclé”, de “neige” ou de “manteau” – et ce pour des raisons différentes et donc sur des dimensions différentes. Ces vecteurs ont ainsi généralement plusieurs dimensions (généralement entre 50 et 300), chaque dimension capturant ainsi un aspect différent du sens d’un mot. Il ne faut pas se représenter les mots dans un espace à 3 dimensions (comme le nôtre) mais dans un espace à 300 dimensions, inconcevable pour l’être humain.
Pour obtenir ces résultats et capturer le sens des mots, ces algorithmes vont ajuster les vecteurs aux mots juste avant et aux mots juste après dans les corpus de texte : au fur et à mesure de l’ajustement sur des grands volumes de données, l’algorithme va faire ressortir des liens entre ces mots. Ces liens peuvent nous être présentés dans un espace à deux dimensions (plus facile à représenter dans un article qu’un espace à 300 dimensions) et mettre en avant certaines proximités sémantiques. Ainsi on voit que les vecteurs entre France et Paris, England et London, ainsi qu’Italy et Rome sont similaires : l’algorithme a capturé le lien sémantique qui connecte une ville et sa capitale.
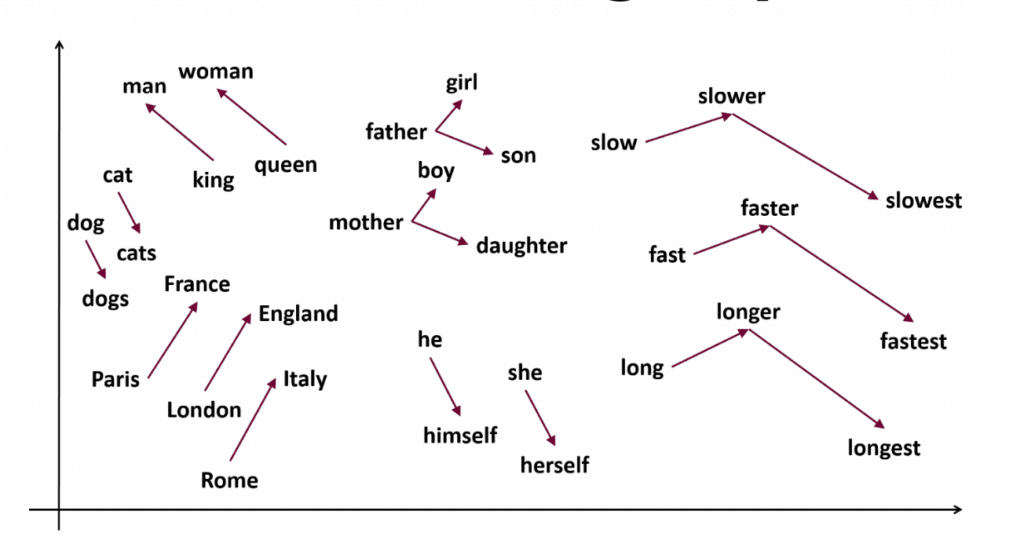
Représentation en 2 dimensions des résultats d’un algorithme de “word embeddings”
Il existe plusieurs techniques et modèles populaires pour créer ces vecteurs, comme Word2Vec, GloVe, ou FastText. Ces modèles observent les cooccurrences de mots dans d’énormes bases de données textuelles pour construire ces représentations vectorielles. On parle d’Encoders pour transformer des textes en vecteurs et de “Decoders” pour transformer des vecteurs en texte.
Une fois ces vecteurs obtenus, il est possible de les utiliser dans diverses tâches d’apprentissage automatique, comme la classification de texte, la traduction automatique, etc. L’une des utilités de ces vecteurs est la capacité de mesurer la similitude entre les mots. Par exemple, en calculant la distance entre les vecteurs de deux mots, on peut obtenir une mesure de leur “similitude sémantique.” En bref, les “word embeddings” traduisent l’information sémantique des mots en une forme que les ordinateurs peuvent traiter efficacement, facilitant ainsi la tâche des modèles d’IA lors du traitement du langage naturel.
Pour en savoir plus, je vous mets ci-dessous le 2ème webinar de l’IAcadémie :
–
Les LLM, des “auto-complete” géants
Un LLM, ou “Large Language Model” est une structure informatique qui a été formée pour analyser et générer du langage humain. Un des plus connus, chatGPT, fonctionne finalement comme un “auto-complete géant” pour reprendre les mots de Stanislas Polu, cofondateur de Dust et ancien ingénieur chez Open AI.
Pour générer du texte, ChatGPT va d’abord passer par une phase d’apprentissage durant laquelle il va ingérer toute la donnée du web. Cela va par exemple lui permettre d’apprendre des structures grammaticales, des faits, des associations entre les mots, des styles d’écriture, etc. Une fois cet apprentissage terminé, et quelques ajustements opérés, ChatGPT va pouvoir générer du texte en suivant les requêtes de l’utilisateur – on parle alors de “prompt” (voir chapitre 3).
Etant donné toutes les informations qu’il a ingéré durant cette phase d’apprentissage, ChatGPT va ainsi être capable de compléter un début de phrase qui lui est proposé ; comme un auto-complete. Et il va le faire mot par mot, via un modèle qu’on qualifie d’auto-régressif. Si on lui donne la phrase “la souris est mangée par…” et qu’on lui demande de la compléter, il va alors émettre des propositions associées à des probabilités : “le” et “la” ont de fortes chances d’être sélectionnées tandis que “cette” a peut-être moins de chance d’être choisi.
Une fois le mot suivant arrêté (ex. “le”), ChatGPT va répéter la même opération en intégrant son choix précédent à son “contexte” c’est-à-dire aux éléments à prendre en compte pour orienter les différentes possibilités qui s’offrent à lui pour le prochain mot. Le mot “vache” est, de fait, éliminé (on ne dit pas “le vache”), tandis que de nombreux mots sont possibles comme “chien”, “chat”, “monsieur”. Ce fonctionnement, qui consiste à générer un mot après l’autre, est qualifié d’auto-régressif. On obtient ainsi la phrase “la souris est mangée par le chat”.
Un LLM essaye donc constamment de prédire la suite logique d’une séquence. Il fait cela mot par mot, jusqu’à ce qu’il atteigne une certaine longueur ou un autre critère d’arrêt. Il est important de noter que, bien que les LLM soient avancés et puissants, ils ne comprennent pas réellement le langage ou le contexte de la même manière que les humains. Ils génèrent des réponses basées sur des patterns observés lors de leur formation, mais sans véritable compréhension.
Ce qu’il se passe c’est qu’à chaque fois que ChatGPT génère le mot suivant, il s’appuie sur un modèle probabiliste, c’est-à-dire qu’il va “sampler” une distribution de mots. En sortie du modèle il n’y a donc pas un seul mot, mais une distribution de probabilité sur l’ensemble des mots possibles. Dans notre exemple, la distribution de probabilité va être très resserrée autour du mot “chat” : en effet les données d’Internet sur lesquelles s’est entraîné l’algorithme, vont plutôt le pousser vers ce choix. Mais quand on demande à ChatGPT de rédiger un texte “à la manière de Victor Hugo”, on va finalement changer le “contexte” utilisé par le système pour générer chaque mot. On va ainsi modifier la distribution de probabilité et potentiellement tomber sur le mot “matou” ou “félin”.
Mécaniquement, en faisant plusieurs fois la même demande, on va aussi tomber sur des résultats différents. On parle alors de “modèles stochastiques”, c’est-à-dire de modèles dont le résultat est aléatoire. Chaque mot (ou token) représente ainsi un embranchement pour lequel le même LLM peut prendre des chemins différents. Chaque mot représente aussi un nouveau lancé de dé imprévisible – même si fortement biaisé par l’apprentissage et le “contexte”.
* * * * *
Note technique : on distingue généralement les modèles “Decoder-Only”, GPT-style qui fonctionne par prédiction auto-regressive pour générer du texte (LLM / LM pour Language Modeling) ; et les modèles Encoder-Only, BERT-style qui fonctionne par “Masked Language Modeling”, c’est à dire en entraînant le modèle sur la base de mots cachés au milieu de phrases. Si jusqu’en 2021, les modèles BERT-style dominaient globalement, 2023 a fait émerger les modèles GPT-style les plus connus et les plus utilisés aujourd’hui comme GPT4, Bard, Claude ou LLamA.
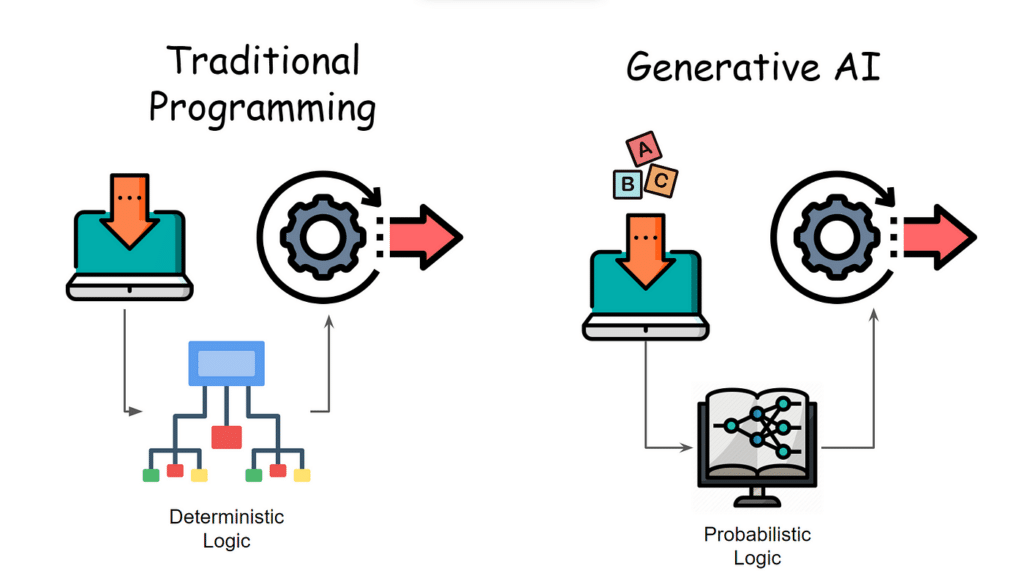
Déterminisme et probabilisme
On voit finalement que les LMM ne sont pas “déterministes” contrairement aux algorithmes classiques comme les calculettes – qui ne font pas d’erreur. On oppose alors les algorithmes déterministes aux LLM probabilistes qui sélectionnent des éléments sur la base de probabilités étant donné un contexte défini. Par construction de ces modèles, la réponse peut donc être fausse ou complètement absurde : on parle alors d’hallucinations. C’est par exemple le cas si le LLM vous propose une phrase comme “la souris est mangée par le pantalon”. C’est peu probable que le LLM sorte ce type de phrase mais c’est statistiquement possible ; et ces erreurs sont inhérentes au fonctionnement des LMM.
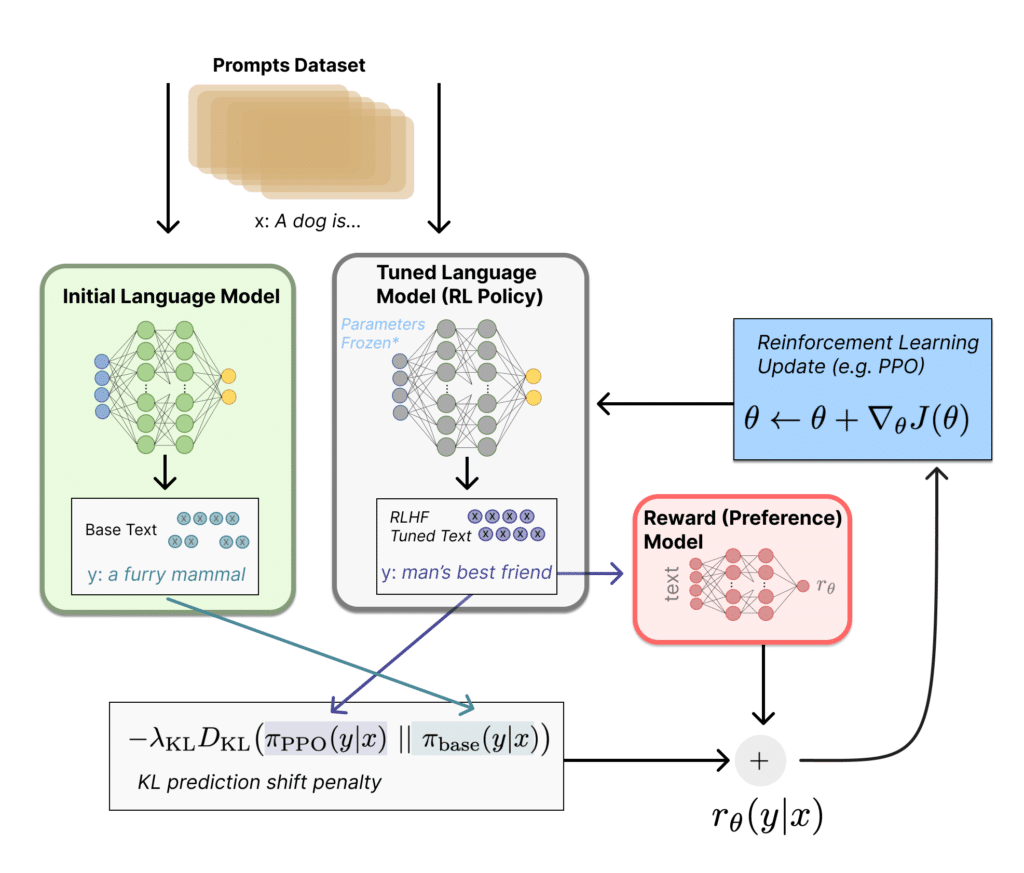
Puisqu’un LLM comme ChatGPT est entraîné sur tout internet, il est aussi intéressant de réfléchir au Machine Learning en termes de compression. Finalement, on demande à un système d’apprentissage, de stocker toutes les informations du web sur la base de valeurs numériques dans un espace mathématique – voir point précédent sur le stockage des mots sous la forme de vecteurs. Ce que des sociétés comme Open AI essayent donc de faire, c’est de compresser la connaissance de tout Internet dans des tableaux beaucoup plus petits. Et c’est une des raisons pour lesquelles ces modèles sont imparfaits : ils ne peuvent pas tout apprendre par cœur et sont donc obligés de générer du contenu avec une certaine forme d’imprécision.
Les deux phases de l’entraînement d’un LLM
Il est aussi intéressant de distinguer deux phases d’apprentissage pour les modèles LLM. La première phase consiste à entraîner le modèle sur une base de données définie – pour chat GPT il s’agissait des données du web 2021. On obtient alors ce que l’on appelle un “modèle pré-entraîné” sur un set de données initial. La deuxième phase consiste a “fine-tuner” le modèle grâce à des méthodes de “renforcement” pour l’adapter plus précisément à un objectif précis. Si cet objectif est d’être mis entre les mains du grand public, il va par exemple falloir exclure les propos racistes, violents, les insultes, etc.
Par ailleurs, un modèle qui sort de la première phase d’entraînement n’est pas en mesure de comprendre certaines tâches qui lui sont demandées comme de résumer un texte, le traduire, l’améliorer, etc. Il est alors nécessaire de fine-tuner le modèle via du “few shot prompting” : il s’agit ici de lui montrer quelques exemples (ou shots) qui lui permettront de comprendre ces tâches et de mieux les reproduire. Or les utilisateurs de ChatGPT n’ont pas forcément envie de fournir des exemples de textes résumés avant que le modèle puisse résumer leur texte. Ce n’est pas la promesse de l’outil ! Il est donc nécessaire de procéder à une surcouche d’entraînement (appelée “instruction following”) sur ce modèle pour lui apprendre à suivre des instructions d’une certaine manière. Ce fine-tuning peut aussi passer par un entraînement sur un sous-set de données plus spécifiques à l’objectif qu’on lui donne.
Dans la plupart des cas, des humains vont enfin annoter les réponses du modèle pour lui indiquer la qualité ou non du contenu généré : on retrouve le concept d’apprentissage par renforcement évoqué en chapitre 1 à propos du machine learning. Les annotateurs vont ainsi lui “encoder certaines préférences”, comme celles de suivre des instructions, de générer du texte informatif et concis, ou de ne pas produire de contenus injurieux par exemple. On parle alors de “Reinforcement Learning through Human Feedback” (RLHF) ou “Apprentissage par renforcement via le retour d’information humain”. L’objectif est de transformer ce modèle en un chatbot, un agent conversationnel avec lequel on pourra interagir facilement et qui produira du contenu intelligible et acceptable socialement. Quand bien même le data-set de pré-entraînement est fixé (web 2021 pour certaines versions de ChatGPT), cette surcouche de renforcement du modèle peut, elle, être faite de manière continue.

Si vous souhaitez en savoir plus sur le sujet du renforcement par RLHF, je vous conseille la lecture de cet article qui introduit la notion de fonction de récompense (ou “reward function”) pour guider l’amélioration du modèle.
Pour bien comprendre le process on peut le résumer ainsi : des annotateurs humains vont tout d’abord étudier des réponses générées par le modèle pré-entraîné et ce pour divers prompts. Il leur est ainsi demandé de comparer plusieurs réponses et de choisir celle qu’ils préfèrent ou d’évaluer la qualité de chaque réponse selon certaines directives. Ces annotations fournissent une base de données de préférences humaines qui sera ensuite utilisée pour former un “modèle de préférence”. C’est sur la base de ce modèle que la “fonction de récompense” va permettre d’ajuster les réponses du modèle pré-entraîné. Dans l’exemple ci-dessous, le modèle est mieux récompensé lorsqu’il dit que “le chien est le meilleur ami de l’homme” que lorsqu’il dit que “le chien est un animal à fourrure”. Et cela va lui ainsi lui “encoder” certaines préférences.
Toutefois, comme le dit lui-même ChatGPT, “il est important de noter que, même avec le RLHF, il est difficile de garantir que le modèle ne produira jamais de réponses indésirables ou incorrectes. La formation et l’évaluation continuent d’être des domaines actifs de recherche en ce qui concerne l’intelligence artificielle.”
On peut ici citer l’exemple du chatbot Tay, lancé par Microsoft en 2016, censé discuter avec des adolescents sur les réseaux sociaux. Plus ou moins pertinent selon les questions posées, l’IA Tay avait néanmoins conquis plus de 23 000 abonnés en moins de 24 heures. Mais, de façon prévisible, les abonnés avaient testé ses limites pour la pousser à tenir certains propos racistes – ce qui avait suscité l’indignation générale et la fermeture du chatbot.
Les biais de l’IA
C’est d’ailleurs ici qu’intervient la notion de biais. En effet, comme Internet est parfois sexiste, haineux et raciste, les laboratoires comme Open AI, sont obligés de fine-tuner les modèles LLM pour encoder certaines préférences. L’objectif est ainsi d’éviter que ChatGPT se livre à des propos de cette nature… Mais même si Internet est en effet biaisé, le renforcement par feedback humain l’est tout autant par nature, puisqu’il est défini à la fois par la “doctrine” des laboratoires mais aussi par les personnalités des annotateurs de ChatGPT – dont le nombre et l’identité demeurent confidentielles. Encoder la préférence de la démocratie sur l’oligarchie à une Intelligence Artificielle, c’est finalement prendre partie pour une certaine doctrine. Et tous les choix de ce type qui sont ensuite fait, vont finalement dans un sens qui n’est ni celui de la majorité (Internet ?), ni une vérité absolue. Il est donc intéressant de comprendre qu’un LLM est biaisé par nature et transpire de choix culturels, politiques et de valeurs qui ne sont pas universels mais sont définis par des laboratoires comme OpenAI.
Et comme l’explique Stéphane Polu, on peut imaginer qu’une grande partie des contenus sur Internet seront un jour produits par ces modèles et transmettront une certaine vision du monde, avec un biais culturel défini par les laboratoires eux-mêmes – notamment via les instructions données à leur annotateurs. Et en améliorant l’anglais d’un texte, en résumant un livre, en écrivant un discours, en rédigeant un mail via ces LLM, nous serons les propagateurs inconscients de ces biais dans une société ou dans une entreprise ; sans que personne ne puisse y faire grand chose… C’est donc un sujet à bien garder en tête dans l’utilisation de ces outils et qui nous tient forcément à cœur chez Partoo.
Intelligence ou algorithme ?
Pour finir ce deuxième chapitre, il est intéressant de se poser la question de « l’intelligence » des LMM au sens commun du terme. Pour Yann Le Cun, chercheur français spécialisé en IA et considéré comme l’un des inventeurs du “deep learning” (prix Turing 2018), il y a encore une grande marge de progression :
« Quand quelque chose ou quelqu’un est capable de parler, on lui attribue généralement de l’intelligence, mais c’est une erreur. On peut manipuler la langue sans penser, sans être intelligent. Et c’est un peu le problème de ces systèmes : ils sont très volubiles, très fluides, très corrects grammaticalement, mais ce qu’ils racontent n’est pas toujours vrai. »
Ainsi, selon Yann Le Cun, les modèles de LLM qui fonctionnent par « prédiction auto-régressive » (ex. ChatGPT4) peuvent difficilement être qualifiés d’intelligents au sens humain du terme ; et ce pour deux raisons :
- D’une part, la réponse apportée par l’IA n’est pas planifiée : « la machine n’a pas réfléchi à l’avance à ce qu’elle allait dire car elle produit un mot après l’autre de manière auto-régressive. »
- D’autre part, l’IA n’a pas conscience du monde, elle n’a pas de compréhension de la réalité sous-jacente : « ces systèmes compensent leur faiblesse de raisonnement par l’accumulation de connaissances tirées de tous les textes possibles d’internet (…) Mais leur connaissance du monde, du monde physique en particulier, est extrêmement réduite : ils n’ont aucune notion de l’existence de la réalité car ils sont purement entraînés sur des textes. Or la grande majorité de l’intelligence humaine est non linguistique car elle s’appuie sur notre expérience du monde réel ; un sens commun que n’ont pas les machines. »
Mais cela ne veut pas dire que cette manière de générer des données n’est pas une forme d’intelligence. Car de ce point de vue, les limites des LLM seraient principalement liées à la nature de leurs données d’entraînement – qui sont uniquement textuelles.
Lorsqu’il évoque l’épineuse question de l’intelligence des LLM, Stéphane Polu est moins catégorique : “je ne sais pas si on peut dire que les modèles ne sont pas intelligents ou qu’ils ne comprennent pas ; il n’y a rien qui démontre qu’on ne fait pas un peu la même chose. C’est juste qu’on a plein de signaux qui sont plus riches que le texte. On a un corps qui nous permet de nous déplacer donc on peut prévoir le monde autour de nous avec des points de vue différents, et cela nous apporte un modèle plus riche qu’un modèle de langage qui ne voit que du texte.
Les capabilités émergentes ressemblent déjà à des capacités d’intelligence : savoir traduire, savoir résumer, savoir créer, savoir calculer, savoir raisonner à un certain niveau. Mais ces modèles ne sont pas encore aussi intelligents que l’humain, même si la définition du mot intelligence reste à clarifier.”

3) L’utilisation de l’IA chez Partoo
Les use-cases
On arrive maintenant à la partie que vous attendez tous, à savoir les cas d’usage que nous envisageons chez Partoo.
Depuis 2018, nous cherchons à mettre à profit la puissance de l’IA auprès de nos clients, à commencer par des applications en back office (pour l’interne), comme le geocoding de points de vente (cf. chapitre 1). Mais de nombreux autres cas d’usage sont possibles. En particulier, nous étudions depuis un moment les algorithmes de “Sentiment Analysis” ou encore la catégorisation d’avis clients par IA.
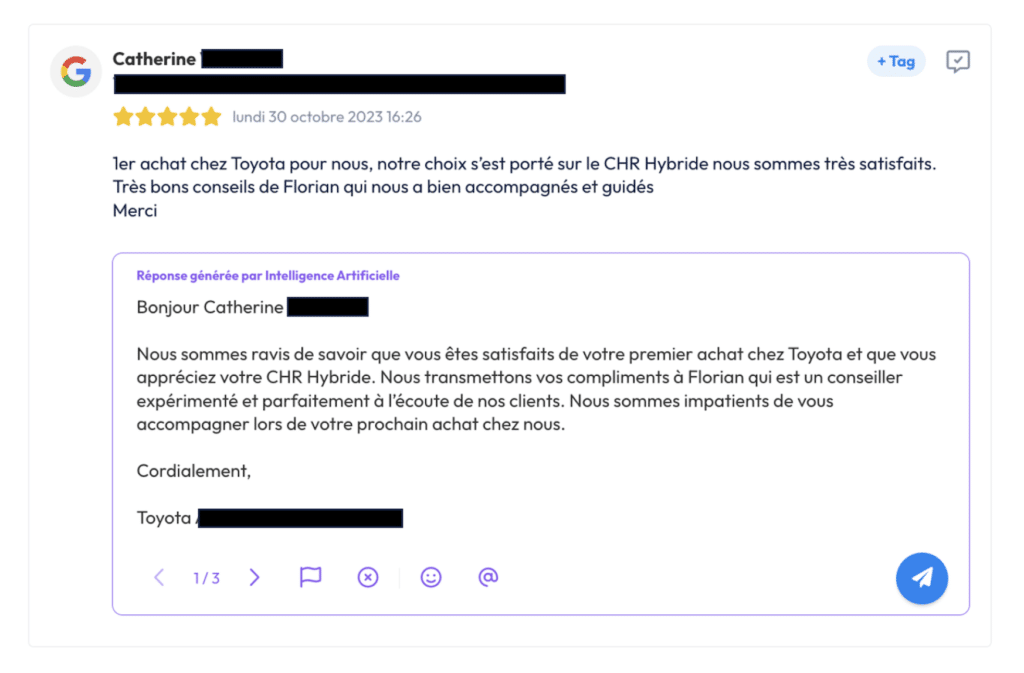
Plus récemment, nous avons développé une fonctionnalité d’IA permettant à nos clients de suggérer par IA de potentielles réponses aux avis de leurs clients. En effet, chaque semaine, les clients de Partoo reçoivent communément plus de 100 000 avis, soit 10 avis par minute ! Et ce chiffre est en forte croissance. Il s’agit principalement des avis sur Google Maps comme vous pouvez le voir dans l’exemple ci-dessous.
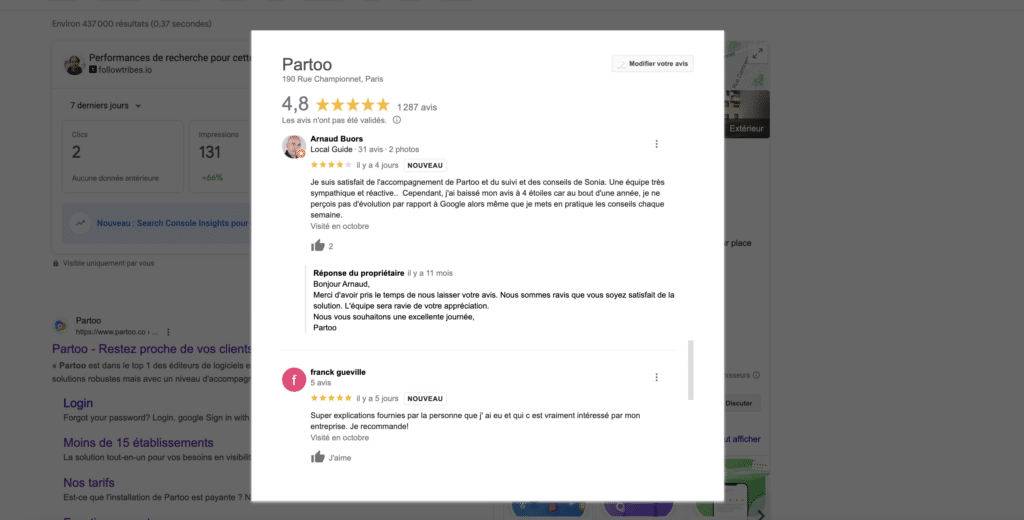
Si, on part du principe que chaque réponse à un avis met quelques minutes à être rédigées, cela représente une quantité de travail colossal, sur laquelle l’IA peut aider. Mais encore faut il s’y prendre correctement. En effet, comme nous l’avons vu précédemment, les LLM sont sources d’erreurs et sont parfois (rarement) sujets à des “hallucinations”.
Pour reprendre les mots de Stanislas Polu (encore une fois), les bons cas d’usage pour les LLM sont “ceux pour lesquels il est plus facile de vérifier le contenu que de le générer”.
Un bon cas d’usage est donc, par exemple, celui de l’outil Copilot de Github. A chaque ligne de code, Copilot va générer des propositions que les développeurs vont pouvoir accepter en appuyant sur TAB ou refuser en continuant à écrire. Il s’agit là du même principe que l’auto-complete sur Gmail ou sur Google Doc. Dans ces cas d’usages, l’aide est précieuse et la vérification est instantanée. Une erreur ne coûte rien car elle est très facilement repérable par l’utilisateur et rapidement mise de côté.

Les suggestions de réponse par IA fonctionnent sur le même principe. Et pour que vous puissiez mieux comprendre comment cela fonctionne chez Partoo, voici donc une vidéo explicative :
Comment prompter ?
Pour comprendre comment nous avons intégré l’IA à Partoo, un dernier concept reste à éclaircir : celui des “prompts”. Un prompt est une entrée ou une instruction donnée à un modèle d’IA pour guider sa réponse ou son comportement. Dans le contexte des LLM comme ChatGPT, il s’agit typiquement du texte que l’utilisateur fournit pour obtenir une réponse ou un texte en retour.
Il est aussi important de comprendre qu’on peut prompter ChatGPT de deux manières : soit en tant qu’utilisateur en accédant directement à la plateforme de ChatGPT, soit en tant que développeur en accédant au service via une API. Pour ce faire, vous devez donc accéder à l’API et choisir un langage de programmation tel que Python ou JavaScript. C’est ce que nous avons fait pour intégrer le modèle de ChatGPT à l’interface Partoo utilisée par des réseaux de points de vente souhaitant répondre plus facilement à leurs avis en ligne.
On dit généralement qu’un prompt comprend 4 éléments distincts :
- Le “system message” à savoir le cadre initial
- Les exemples (les shots)
- Les paramètres
- Le “user message”, c’est-à-dire ce qu’on lui demande
Regardons ensemble chacun des éléments qui définissent un prompt.
1) Le “system message”
C’est une instruction initiale ou un cadre donné au modèle. Il décrit généralement les règles ou les directives selon lesquelles le modèle doit opérer. Par exemple, si vous voulez que le modèle réponde comme Victor Hugo, le “system message” pourrait être : “Vous êtes Victor Hugo, le célèbre dramaturge. Répondez aux questions dans son style.”
2) Les exemples
Les exemples sont des paires “question – réponse” qui fournissent un contexte supplémentaire au modèle. Ils aident le modèle à comprendre le type de réponse attendu. On retrouve ici le concept de “few shot prompting” visant à donner au modèle des exemples de réponses attendues à certaines questions.
3) Les paramètres
Différents paramètres influencent le comportement du modèle lors de la génération de réponses.
Un des principaux est la “température” : elle détermine le niveau d’originalité ou de variabilité de la réponse. Une température plus élevée rend la sortie plus aléatoire, tandis qu’une température plus basse la rend plus déterministe et concentrée sur les réponses les plus probables.
Dans l’exemple proposé en chapitre 2, une température plus élevée à plus de chance de dire que “la souris est mangée par le pantalon” alors qu’une température plus basse tombera plus souvent sur “la souris est mangée par le chat”. Baisser la température resserra la distribution probabiliste autour d’une valeur plus “crédible” mais limitera l’inventivité du modèle. La valeur typique de la température est généralement comprise entre 0,2 (réponse très cohérente) et 1,0 (plus variée et créative).
Un deuxième exemple de paramètre est celui de la mémoire (ou “token limit”) qui correspond à la longueur de l’entrée et de la sortie. Les modèles comme GPT-3 ont une limite sur le nombre de tokens (morceaux de texte) qu’ils peuvent traiter en une seule fois. Si un prompt est trop long, il peut alors être nécessaire de le tronquer ou de l’adapter.
4) Le “user message”
C’est la question ou l’instruction actuelle donnée par l’utilisateur après avoir fourni les éléments ci-dessus. Dans notre exemple Victor Hugo, cela pourrait être : “Décrivez la beauté de la nature.” Le modèle, en se basant sur le “system message”, les exemples et les paramètres donnés, répondra d’une manière qui évoque le style de Victor Hugo.
* * * * * *
Une fois ces éléments définis, il convient d’améliorer le prompt par l’analyse des retours et d’avancer pas à pas. Il peut alors être conseillé d’utiliser des verbes et des mots forts. Plutôt que d’écrire en prompt « réécris ce texte », il est préférable de dire « clarifie ce texte ». Préférez aussi la forme positive, en ne demandant pas « n’écris pas de manière familière » ou « n’écris pas à la forme passive », mais « écris de manière soutenue » ou « écris à la forme active ».
Comment avons nous prompté chat GPT dans le cas de Partoo ?
Intéressons nous maintenant au cas d’usage de Partoo, à savoir la réponse aux avis des internautes sur Google Maps, Facebook Local et Tripadvisor. Pour répondre à ce besoin très précis, les équipes de Partoo (en particulier notre Product Manager sur le sujet, Vincent Lespinasse ainsi que notre CPO, Savinien Lucbéreilh) ont rédigé les différents éléments de notre prompt comme suit.
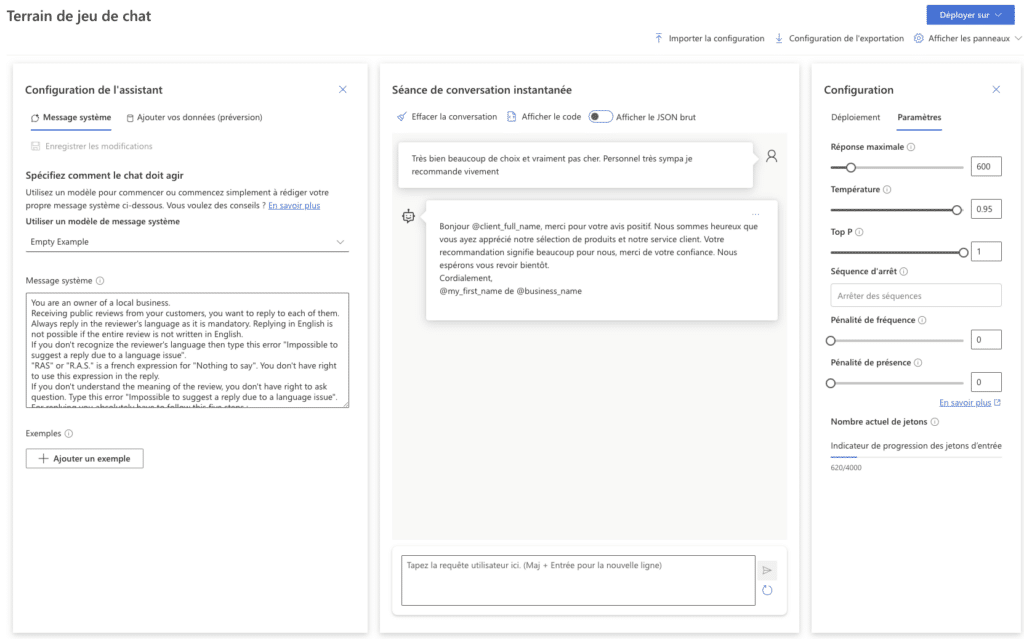
Le “system message” de notre modèle est tout d’abord assez simple et commence par une affirmation très directe : “You are an owner of a local business. Receiving public reviews from your customers, you want to reply to each of them, always in the reviewer’s language.“
Partoo ayant des clients dans plus de 150 pays, il est important que les suggestions de réponse se fassent dans la langue de l’internaute qui a laissé l’avis. Et puisque dans les LLM les mots ne sont finalement que des vecteurs dans des espaces mathématiques multidimensionnel, la question de la langue est anecdotique ! Pour une société internationale comme Partoo, se dire que le modèle final fonctionnera ensuite dans toutes les langues reste cependant très agréable.
Les paramètres ont ensuite été définis comme assez permissifs pour avoir un maximum d’inventivité au niveau des réponses. Ainsi la température a été fixée à 0.95 ce qui est très proche de 1 et donc assez “ouvert”. Comme nous l’avons vu, cela permet d’obtenir des réponses créatives et donc des effets “waouh” (ce qui était l’effet recherché par cette fonctionnalité) ; cependant cela peut aussi générer plus d’hallucinations – c’est-à-dire d’absurdités.
Afin de valider cette température, nous avons confirmé empiriquement que, sur 3 essais, le modèle donne en général au moins une réponse satisfaisante – et ce dans plus de 95% des cas. Ainsi, si l’utilisateur n’est pas satisfait par la réponse suggérée par l’IA, il a la possibilité de générer une deuxième réponse, puis une troisième. Et de choisir celle qui lui convient.
Dans l’exemple ci-dessous, on voit ainsi que la réponse est plutôt poussée, avec une reformulation du texte (“1er achat” vs. “premier achat”). Cependant un risque est pris : il n’est pas évident que Florian soit “expérimenté”, il pourrait au contraire être très junior. Par ailleurs, la phrase “nous espérons vous accompagner lors de votre prochain achat” ne fonctionnerait pas pour une visite dans un hôpital. Il est donc important de garder à l’esprit que ce type de fonctionnalité est une aide aux traitements des avis et non un remplacement du traitement humain.
Le “user message” est quant à lui très précis pour que le cadre soit clair et qu’il n’y ait pas d’erreur dans les réponses : “You always must use a formal language and consider that the reviewer is singular. You are polite, formal, professional and empathetic with your customer even if they are angry. Important : Tone must be assertive, optimistic and friendly.” etc
Mais la rédaction du prompt ne s’arrête pas à ces 4 éléments, et le prompt que nous avons rédigé pour ce cas d’usage est ainsi bien plus long.
Il est par exemple indispensable de définir des contraintes spécifiques au prompt pour guider davantage la réponse. Dans le cas de Partoo, nous avons demandé au modèle de ne pas utiliser les mêmes termes que le client (pour éviter les effets de répétition), ne pas faire d’offres promotionnelles ou de fausses promesses.
Autre exemple intéressant pour l’anecdote : nous avons observé que le modèle de réponse aux avis de Partoo buguait lorsque l’avis comprenait le mot RAS. Nous avons donc ajouté dans le prompt une ligne dédiée à ce cas spécifique : “RAS” or “R.A.S.” is a French expression for “Nothing to say”. Or, en prenant en compte cet élément du prompt, le modèle a commencé à lui-même utiliser RAS dans certaines de ses réponses, ce qui n’est pas idéal pour répondre à des clients. Nous avons ainsi été obligés d’ajouter une ligne additionnelle, précisant : “You don’t have the right to use this expression in the reply.”
Et après ?
Ce qui est intéressant avec les ruptures technologiques, c’est que la recherche fondamentale ouvre la voie à un nombre phénoménal d’applications business qui sont souvent inventées sur le temps long : pour l’intelligence artificielle, tout reste à faire. Il y a un vrai boulevard pour appliquer cette technologie au business sur des cas d’usage précis.
En prenant du recul, on peut même analyser les ruptures technologiques sous la forme de trois vagues successives. La première correspond à la recherche scientifique, la deuxième à la compréhension par le grand public, la troisième vague correspond, elle, à la mise à profit de cette technologie par les entreprises.
Sam Altman, le fondateur d’Open AI, explique ainsi que le lancement de ChatGPT ne correspond pas à une véritable rupture technologique en matière d’IA. La recherche sur ces sujets a en effet progressé de manière continue au travers de diverses innovations comme le “word embedding” (2013), le Deep Learning (2018) ou les nouveaux modèles LLM (2023). De la même manière, il ne prévoit pas de rupture à venir avec ChatGPT5 ou 6. Ce sera principalement des améliorations incrémentales. Il prend ainsi l’exemple de l’Iphone : chaque nouveau modèle apporte des innovations qui sont incrémentales par rapport au précédent ; mais le public a le sentiment que le produit évolue peu. Pourtant, si vous prenez un Iphone 3 et un Iphone 15 dans les mains vous verrez facilement la différence – qui peut être alors vue comme une “rupture”.

Mais alors pourquoi avons nous eu le sentiment d’une rupture technologique avec la sortie de ChatGPT ?
La raison, selon Altman, c’est qu’il y avait un vrai décalage entre l’avancée des recherches scientifiques et la compréhension de ces avancées par le grand public : cela aurait pu continuer pendant longtemps mais ChatGPT a brisé ce décalage en révélant au grand public la puissance de l’IA générative. Nous sommes donc au début de la 3ème vague : la technologie est là, le monde en a conscience, reste aux entreprises à en tirer des applications business !
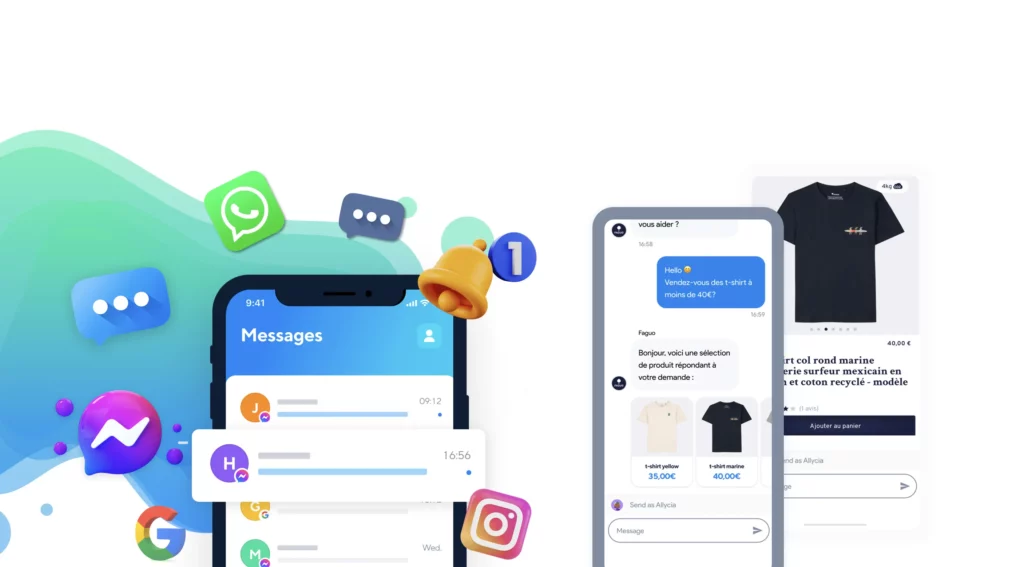
Chez Partoo, nous avons identifié de nombreux cas d’usages, que ce soit sur la catégorisation des avis ou leur traitement par suggestion de réponse. Pourtant, il ne s’agit pas là des applications les plus excitantes auxquelles nous réfléchissons. En effet, nous avons l’ambition, à terme, de révolutionner la manière dont les entreprises interagissent avec leur clients via ce qu’on appelle le “commerce conversationnel”.
Le commerce conversationnel, notre cheval de bataille
Chaque année, les 300 000 points de vente qui utilisent la technologie Partoo dans le monde reçoivent plus d’un milliard d’appels téléphoniques : pour un réseau comme Leclerc, cela représente 20 millions d’appels par an. C’est un coût humain et financier colossal pour ces entreprises ; sans compter les problèmes de “non décroché” au téléphone qui dégradent la satisfaction client sur le long terme ! Vous en avez peut-être fait l’expérience.
Mais il y a une solution à cette problématique. En effet, 90% des consommateurs préfèrent échanger avec une entreprise par messagerie instantanée plutôt que par téléphone. Il y a donc moyen de désengorger les centres d’appels et faciliter la vie des points de vente en remplaçant le canal téléphonique par des canaux de messagerie instantanés plus facilement automatisables. C’est la raison pour laquelle, chez Partoo, nous avons développé une technologie qui permet aux points de vente de centraliser tous les messages de leurs clients, qu’il s’agisse de SMS, d’appels manqués, de messages Facebook, Instagram, Whatsapp et demain LinkedIn, Twitter, etc.
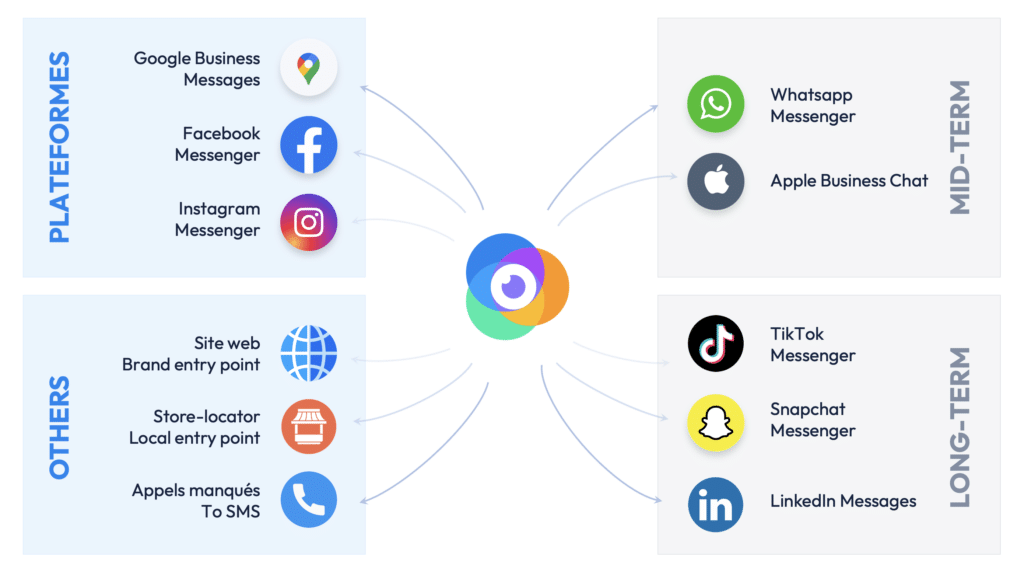
Plus d’une centaine d’enseignes françaises testent ainsi nos technologies de messagerie en France, et ce, dans tous les secteurs (Toyota, Crédit Agricole, MeilleurTaux…). Et le nombre de messages que nos clients reçoivent est en constante augmentation : nous venons tout juste de dépasser le million !
Mais en quoi l’IA vient-elle jouer un rôle dans cette révolution ?
Tout simplement car l’IA va rendre possible le traitement automatique d’une grande partie des questions des internautes. C’est finalement le renouveau des chatbots qui fleurissaient dans les années 2010 – 2015. Et pour ce faire, il suffit juste aujourd’hui de fournir aux algorithmes d’IA les bonnes informations pour répondre aux requêtes des clients.
Ces informations peuvent provenir de multiples sources. Il peut s’agir d’informations propres au point de vente comme les horaires, ou les informations de contacts (qui sont déjà stockées dans la base de données de Partoo). Il peut aussi s’agir d’informations facilement formalisables via des FAQs. Par exemple, si nous renseignons dans une interface la question “Peut-on entrer chez Leclerc Soustons avec un animal de compagnie ?” et la réponse “oui s’il est en laisse”, alors l’algorithme d’IA sera en mesure de répondre aux questions “Puis-je venir avec mon chien?” ou encore “les chats sont-ils autorisés ou doit-on les laisser dans la voiture ?”.
Mais au-delà des questions simples de ce type, on peut imaginer des cas d’usage plus complexes en connectant l’IA à des bases de données propres aux points de vente comme les stocks produits ou la base de données produit (le PIM ou Product Information Management). Grâce à toute cette donnée, l’IA pourra répondre à des questions comme “Avez vous des céréales coco pops en stock dans votre magasin ?” ou “quel est le nutri-score de vos coco pops ?” ou bien “pouvez vous me proposer des céréales que vous avez en stock et qui ont un nutri-score B au minimum ?”.
Plus l’IA sera connectée aux bases de données de l’entreprise, plus elle pourra répondre à des questions variées. On peut ainsi imaginer connecter l’IA à un OMS (Order Management System) pour gérer les commandes, à un système de prise de rendez-vous, à un CRM ou à tout autre type de base de données permettant de traiter de nouveaux cas d’usage.
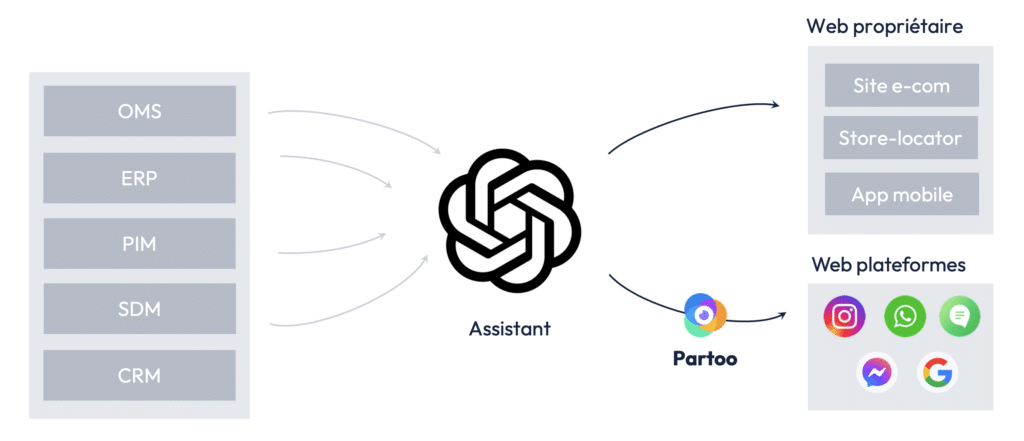
Présentation interne de Partoo
C’est donc un champ des possibles infini que nous regardons avec de plus en plus d’attention chez Partoo. Mais c’est un sujet trop vaste pour être traité ici, j’ai donc rédigé un article spécifique sur le blog de Partoo qui détaille les avantages de l’IA générative vs les arbres de décision et les anciens modèles d’extraction de texte : pour le lire c’est par ici !
* * * * * *
J’espère que cet article vous a appris certaines choses sur l’IA et vous a donné envie d’en savoir plus ! Si vous souhaitez creuser les impacts de l’IA sur la manière dont nous utilisons internet, je vous conseille de vous renseigner sur BARD et Google SGE (Search Generative Experience) : en particulier vous pouvez vous référer à cet article que j’ai écris en Juillet 2023 sur le Journal du Net.
De mon côté, je suis très preneur de retours sur cet article notamment si vous voyez d’éventuelles corrections que je devrais apporter.
Enfin, si vous souhaitez le partager autour de vous, n’hésitez pas : c’est dans cet unique objectif que j’ai pris le temps de l’écrire 🙂