
Si vous vous intéressez à l’IA générative, vous devez avoir entendu parler du RAG pour Retrieval-Augmented Generation. Mais si vous en avez déjà entendu parler, savez-vous comment cela fonctionne précisément ?
Dans cet article nous allons nous pencher sur les aspects techniques du RAG avec un exemple concret : les 7 tomes de la série Harry Potter.
Cet article est tiré du de la première partie du 5ème webinar de l’IAcadémie, une formation gratuite, ouverte à tous (dispo sur Youtube) et bénévole sur les sujets d’IA. Voici le replay du webinar 5 qui comprend notamment un partie sur le RAG Agentic :
I) À quelle problématique le RAG répond-il ?
Un modèle « pré-entrainé » comme GPT4 ou Gemini a été entrainé sur des données figées dans le temps – qui datent de son entrainement. Ré-entrainer le modèle avec de la donnée additionnelle / à jour couterait bien trop cher…
Pourtant, dans l’usage que nous faisons des LLM, il est souvent indispensable que le modèle ait accès à des informations spécifiques / à jour. Une solution simple serait d’envoyer toute la donnée source au LLM à chaque question : le modèle aurait alors la question + toutes les données lui permettant de formuler une réponse.
Mais cette méthode a des limites… auxquelles le RAG vient répondre !
Prenons un exemple simple : celui de Jim, l’agent IA développé par Partoo qui permet aux enseignes de traiter les demandes entrantes de leurs clients sur WhatsApp, Messenger ou leur site internet.
Imaginons un utilisateur qui demande à Jim sur le site web de Leclerc à quelle heure ouvre le Leclerc de Strasbourg. Pour répondre, l’IA doit accéder à une base de données contenant les horaires de chaque magasin. Sans RAG, une solution serait d’envoyer l’intégralité de cette base — horaires, adresses, consignes de ton, contexte conversationnel — dans le prompt à chaque question.
Cette approche se heurte à plusieurs limites structurelles :
- Une limite technique : les modèles de langage ont une capacité maximale d’entrée, appelée context window, au-delà de laquelle ils ne peuvent plus traiter d’informations. Même si cette capacité augmente avec les nouveaux modèles comme Lama-4 (jusqu’à 10 millions de tokens), elle reste finie. Pour en savoir plus, vous référez à cet article.
- Un coût élevé : envoyer toute l’information à chaque requête représente une charge financière significative, proportionnelle au volume de données injecté.
- Une latence trop élevée : plus l’IA doit traiter d’informations, plus le temps de réponse augmente. Si cette latence est tolérable pour du chat écrit, elle devient problématique pour des interfaces vocales comme les voicebots, où l’instantanéité est cruciale.
II) Comme fonctionne le RAG ?
C’est ici qu’intervient le RAG. Au lieu de tout envoyer, le système identifie d’abord — via un moteur de recherche intelligent — les quelques documents ou extraits les plus pertinents en fonction de la question posée. Seuls ces éléments sont ensuite injectés dans le prompt du modèle génératif. Résultat : la réponse reste précise, tout en réduisant la charge, les coûts.
Plutôt que d’envoyer toutes les données disponibles à chaque fois qu’une question est posée, on adopte une logique en deux temps : d’abord retrieve, ensuite generate.
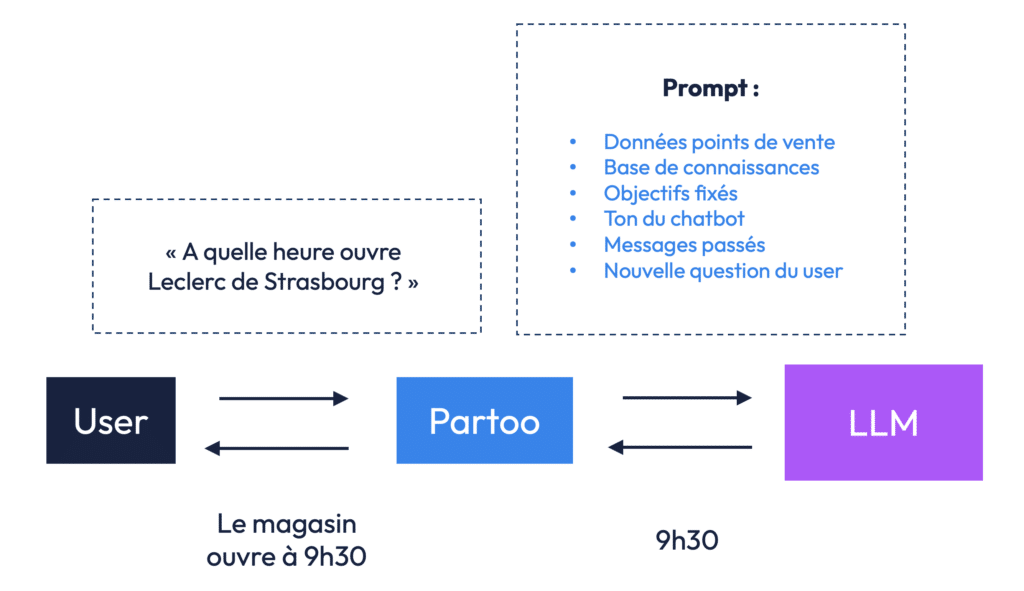
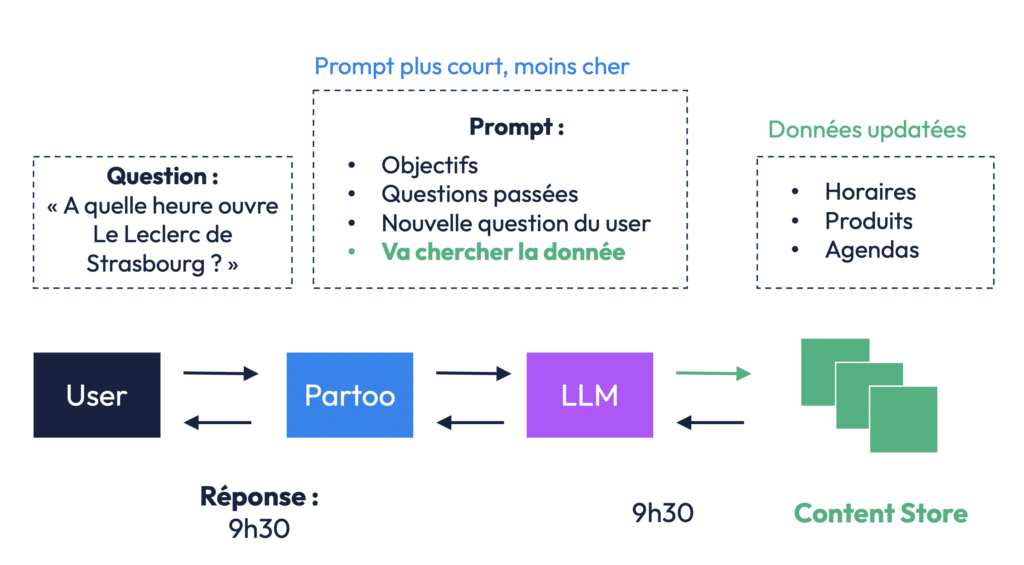
Reprenons l’exemple de l’utilisateur qui demande : « À quelle heure ouvre le Leclerc de Strasbourg ? »
Au lieu de charger l’intégralité des horaires de tous les magasins dans le prompt, Partoo envoie au LLM (large language model) un prompt allégé qui contient uniquement :
- l’objectif de la réponse (ex. : répondre à un client de manière claire),
- le contexte des échanges précédents,
- et la question elle-même.
Mais surtout, on demande au système de récupérer les seules données utiles dans un content store, c’est-à-dire une base de connaissances spécialisée, contenant par exemple les horaires, produits, ou événements par point de vente. Une fois l’information trouvée — ici, que le magasin ouvre à 9h30 — elle est injectée dans le prompt, puis le modèle peut générer une réponse pertinente et concise.
Ce mécanisme permet d’optimiser à tous les niveaux :
- moins d’énergie consommée, car moins de texte est traité ;
- moins de coûts, car les appels au modèle sont plus légers ;
- moins de latence, donc des réponses plus rapides.
Une architecture adaptée à la réalité des données
Pour bien comprendre la puissance du RAG, il faut aussi comprendre la nature des données qu’il mobilise. Dans le monde réel, on distingue généralement deux grands types d’informations :
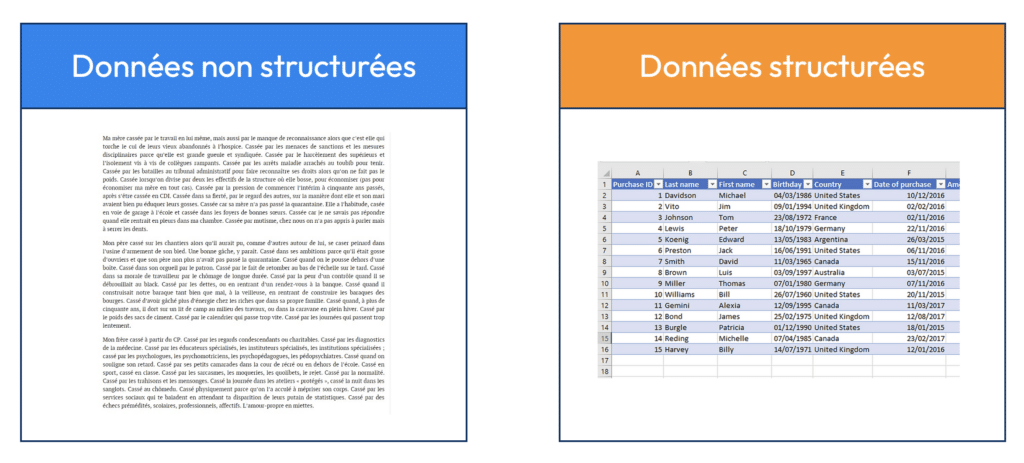
- Les données structurées : organisées sous forme de tableaux, elles sont faciles à manipuler — horaires, prix, coordonnées, etc.
- Les données non structurées : beaucoup plus nombreuses, elles incluent des textes libres, pages web, documents PDF, images, vidéos… Ces données sont souvent riches mais difficiles à exploiter sans traitement avancé.
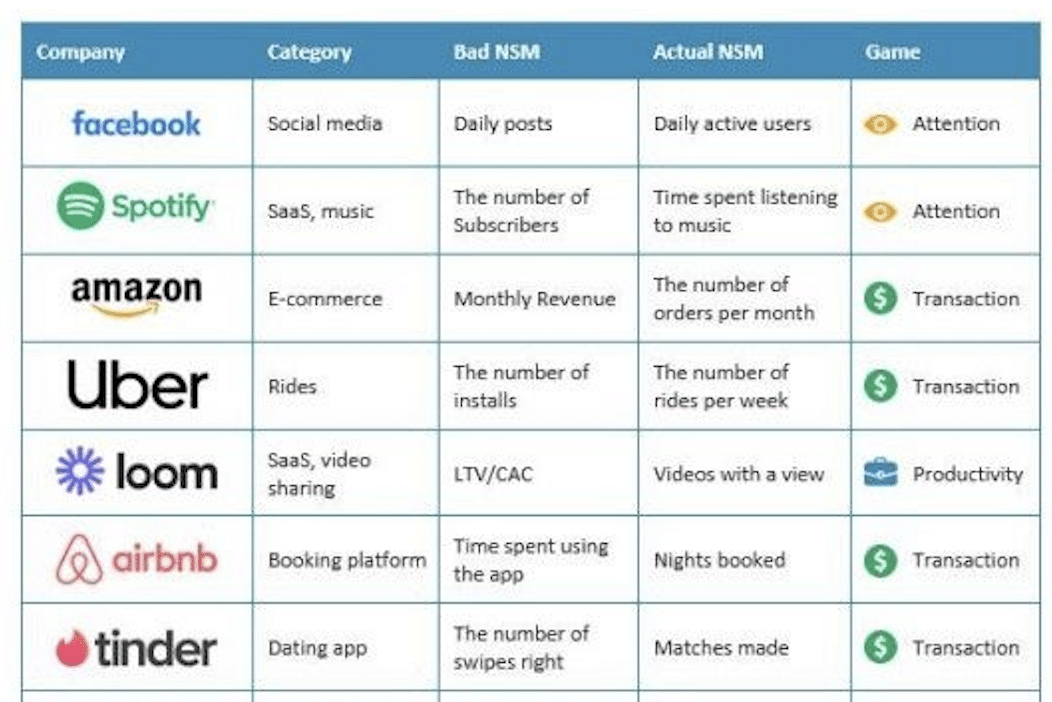
L’un des grands avantages du RAG est justement sa capacité à extraire de la valeur de ces données non structurées, en allant chercher uniquement ce qui est pertinent au moment où l’utilisateur le demande. Dans le prochain chapitre, nous nous focaliserons sur le Vector Index Search, une méthode utilisée pour appliquer du RAG sur des données non structurées.
III) Le RAG pipeline : comment fonctionne concrètement cette architecture ?
Pour comprendre comment un système RAG (Retrieval-Augmented Generation) fonctionne en profondeur, il faut s’intéresser à ce qu’on appelle le RAG pipeline. C’est une chaîne de traitement en plusieurs étapes, conçue pour permettre à une IA de répondre avec précision à une question, en accédant dynamiquement à des données externes, qu’elles soient structurées ou non.
Prenons un exemple très concret : imaginons que vous vouliez créer un chatbot qui connaît parfaitement l’univers d’Harry Potter (et supposons ici que le modèle pré-entrainé que vous utilisez ne connaisse pas Harry Potter). Votre objectif est qu’un utilisateur puisse lui poser n’importe quelle question sur les livres, et que l’IA puisse répondre précisément, en s’appuyant sur les textes eux-mêmes.

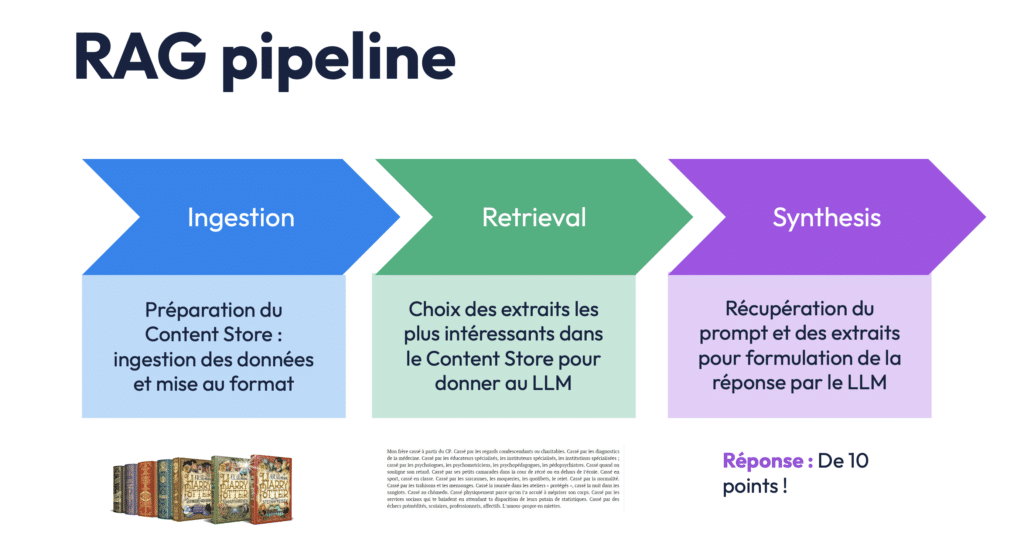
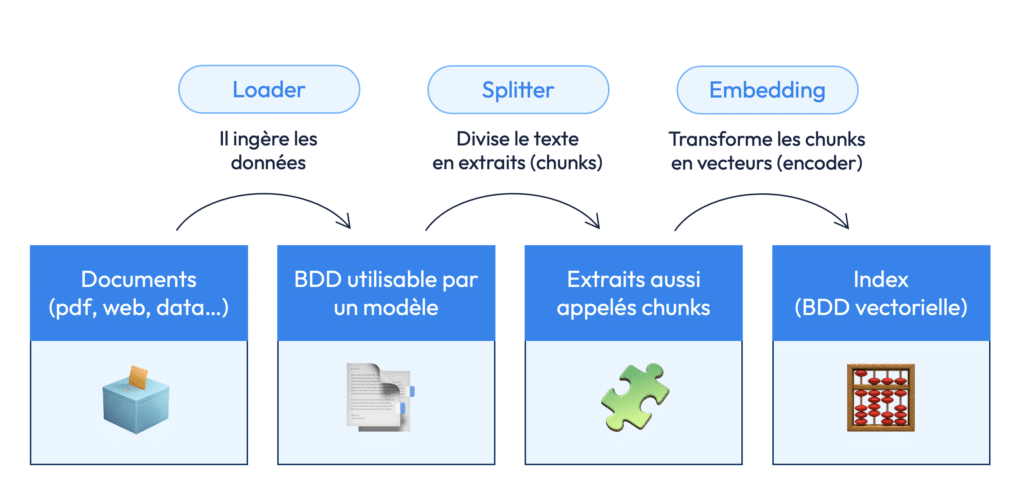
Étape 1 : L’ingestion des données – transformer l’information brute en base exploitable
La première phase du pipeline RAG s’appelle l’ingestion. Il s’agit de prendre des données non structurées (comme des documents texte, des pages web ou des fichiers PDF) et de les transformer pour qu’elles deviennent compréhensibles, interrogeables et exploitables par une intelligence artificielle.
Cette étape est essentielle, car un modèle d’IA, aussi performant soit-il, ne peut pas exploiter directement des données brutes sans un minimum de préparation.
L’ingestion suit généralement trois sous-étapes fondamentales : loading, splitting, et embedding.
a) Le loading : charger et nettoyer les documents
Tout commence par ce qu’on appelle le loading, ou chargement des documents. L’objectif ici est simple en apparence : il s’agit de prendre des fichiers bruts, souvent hétérogènes dans leur format et leur structure, et de les importer dans un environnement technique unifié.
Cela peut inclure :
- des fichiers PDF (rapports, CGV, contrats),
- des pages web (FAQ, documentation produit),
- des documents Word,
- des e-mails archivés,
- ou même des captures de bases de données en format texte.
Mais ce chargement n’est pas un simple copier-coller. Il faut nettoyer les contenus :
- retirer les éléments non pertinents (en-têtes, pieds de page, numéros de page, publicité),
- corriger les caractères spéciaux, les sauts de ligne mal placés, les erreurs d’encodage,
- et, dans certains cas, unifier la langue ou le format du texte.
Cette étape de nettoyage garantit que les données envoyées aux étapes suivantes sont cohérentes, lisibles, et prêtes à être segmentées sans bruit parasite. Un document mal nettoyé peut fausser totalement l’étape d’embedding et produire des réponses incohérentes à l’arrivée.
b) Le splitting : découper les documents en chunks exploitables
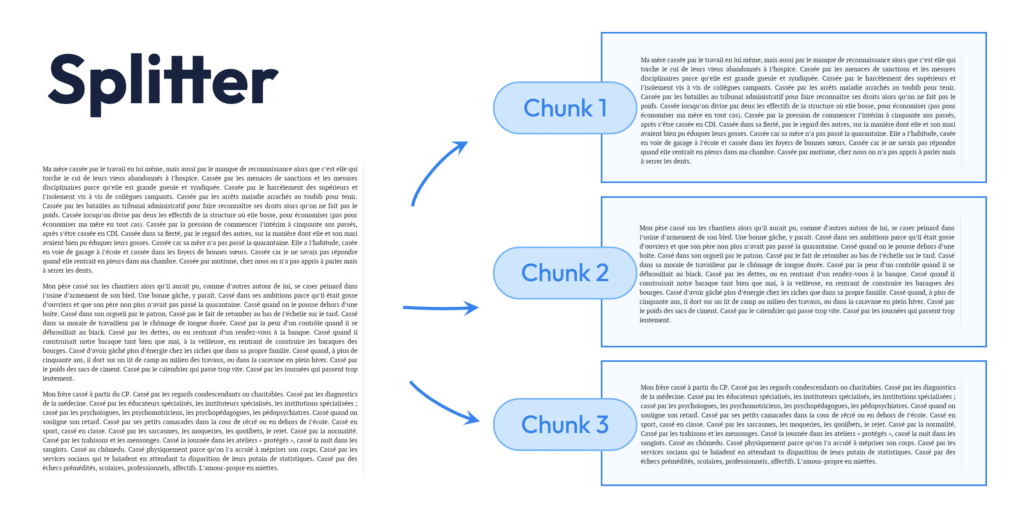
Une fois le document proprement chargé, on passe à la découpe, appelée splitting. C’est une phase stratégique, car elle consiste à diviser le texte en unités appelées chunks, que le système pourra ensuite analyser individuellement.
Mais pourquoi découper ? Parce qu’un modèle de langage ne peut pas ingérer un document entier à chaque question. Il a besoin d’unités d’information plus petites, mais suffisamment riches pour conserver du contexte.
En général :
- un chunk correspond à un paragraphe complet ou à un bloc de quelques phrases,
- la taille optimale dépend du contexte d’usage, mais on cherche souvent à rester autour de 200 à 500 tokens (c’est-à-dire unités de texte),
- des chunks trop longs ralentissent la recherche et augmentent le coût, tandis que des chunks trop courts perdent en contexte et peuvent générer des réponses superficielles.
Cette découpe peut se faire de manière :
- naïve (par paragraphe ou par nombre fixe de tokens),
- ou intelligente, en s’appuyant sur des règles sémantiques : détecter les titres, les changements de sujet, ou les sauts logiques dans le texte.
Ce travail sur le splitting est crucial. C’est ce qui permet de maximiser la pertinence des résultats lors de la recherche, tout en minimisant le bruit.
c) L’embedding : représenter chaque chunk sous forme de vecteur
Dernière sous-étape de l’ingestion : l’embedding. Ici, chaque chunk est transformé en vecteur, c’est-à-dire en représentation mathématique dans un espace à haute dimension.
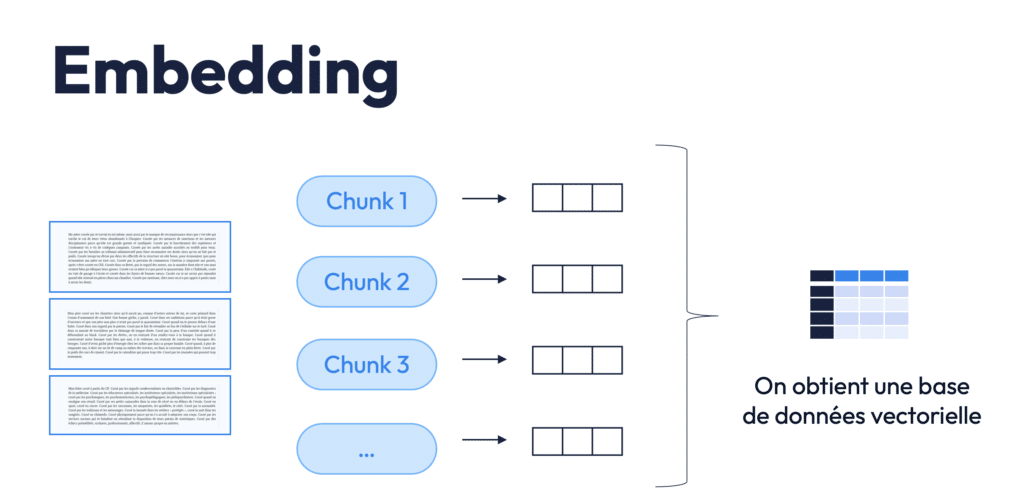
Comment ça marche ?
Un modèle d’embedding lit le chunk, comprend ses thèmes principaux (même de manière implicite), et lui associe un vecteur — une série de nombres qui encode le sens du texte. Par exemple, un paragraphe qui parle de Quidditch, de l’Irlande et d’un match sportif sera représenté par un vecteur dont les dimensions captent ces notions.
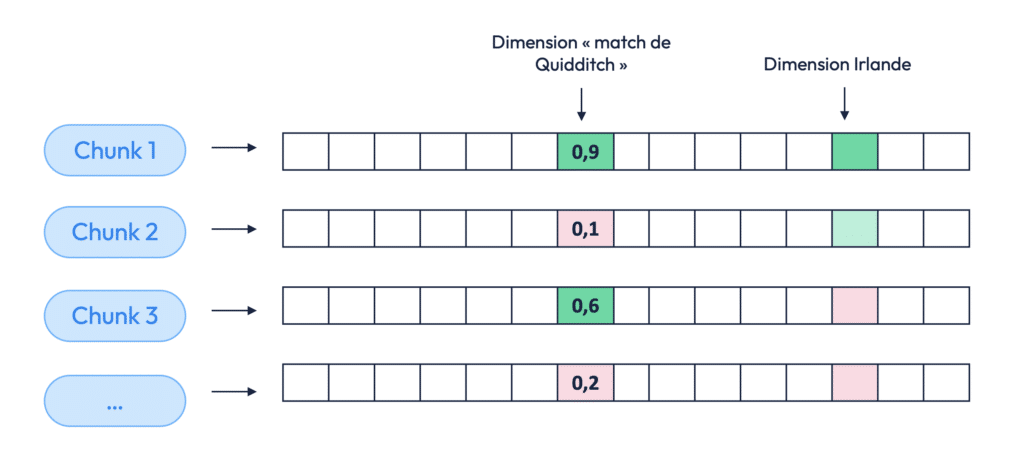
Cet espace vectoriel n’est pas visible, mais il fonctionne comme une carte mentale de sens :
- Deux chunks qui parlent de la même chose seront proches dans cet espace, même s’ils utilisent des mots différents.
- À l’inverse, deux chunks qui parlent de sujets sans lien (par exemple, un sur le Quidditch, l’autre sur les recettes de cuisine) seront éloignés.
Ce mécanisme permet à l’IA de faire des recherches non plus basées sur les mots-clés exacts, mais sur le sens profond des textes.
Tous les vecteurs sont ensuite stockés dans ce qu’on appelle une base vectorielle, qui devient la fondation du content store utilisé dans la phase de retrieval. Cette base est interrogée en temps réel à chaque question posée à l’IA.
Si on résume, la première étape d’Ingestion se structure en 3 étapes :
- Loader
- Splitter
- Embedding
2) Etape 2 : le Retrieval ou comment l’IA sélectionne les bons contenus
Maintenant que les données ont été nettoyées, découpées en chunks, puis transformées en vecteurs dans une base vectorielle, une autre question se pose : comment choisir, parmi tous ces morceaux de texte, ceux qui vont permettre au modèle de répondre avec justesse ?
C’est précisément le rôle de la deuxième étape du pipeline RAG : la phase de retrieval.
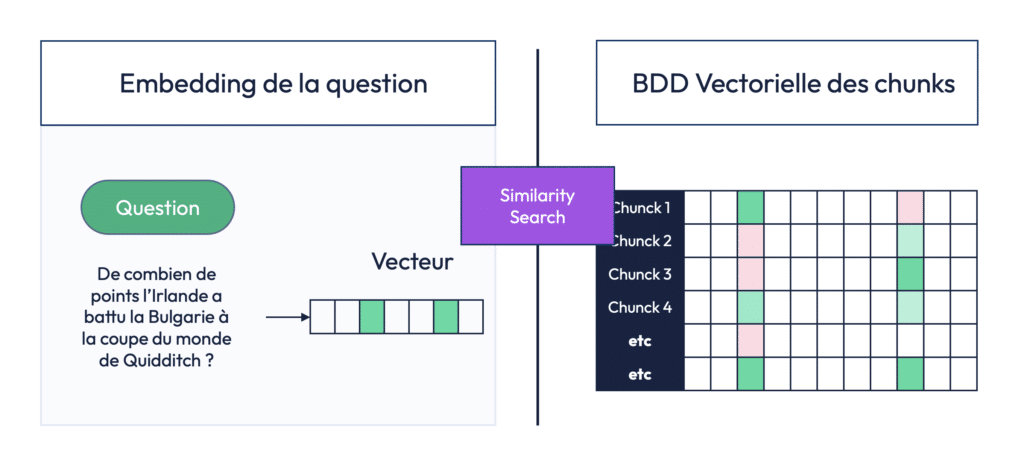
a) Embedding de la question
Tout commence par la transformation de la question utilisateur en vecteur. Imaginons que l’utilisateur demande : « De combien de points l’Irlande a-t-elle battu la Bulgarie à la Coupe du Monde de Quidditch ? »
Cette phrase est passée dans un modèle d’embedding, qui extrait automatiquement ses dimensions sémantiques principales. Ici, ce seront probablement des concepts comme Quidditch, Irlande, Bulgarie, score, match, etc. Ces notions sont encodées dans un vecteur numérique, dans un espace à plusieurs centaines de dimensions. Cela permet une interprétation plus profonde de la signification de la question, au-delà des simples mots clés.
b) Recherche de similarité
Une fois la question vectorisée, le système effectue ce qu’on appelle une similarity search, ou recherche par similarité. Cette méthode va comparer le vecteur de la question à tous les vecteurs présents dans la base de données vectorielle construite à partir des documents (les fameux chunks).
Si certains chunks partagent des dimensions proches avec la question — par exemple, parce qu’ils mentionnent aussi « Quidditch », « Irlande » et « match » — alors ils seront considérés comme sémantiquement similaires. Ils sont donc sélectionnés.
Dans notre exemple, le système va identifier un ou plusieurs paragraphes du tome 4 d’Harry Potter qui parlent précisément du match entre l’Irlande et la Bulgarie, et notamment du score de 170 à 160. Ces chunks sont extraits automatiquement, sans que le modèle ait besoin de « relire » l’ensemble des livres.
3) Envoi au LLM et génération de la réponse
Une fois les chunks pertinents sélectionnés, ils sont envoyés avec la question au LLM. Ce dernier lit la question et les extraits de texte fournis, et produit une réponse naturelle, fluide et adaptée.
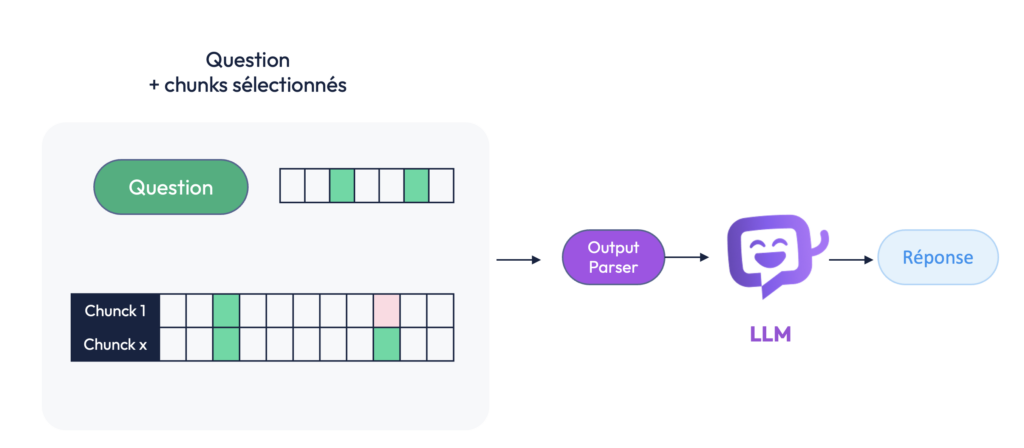
C’est là qu’on mesure toute l’efficacité du pipeline RAG :
- Avant, il aurait fallu injecter tous les livres d’Harry Potter dans le prompt à chaque question — une opération coûteuse, lente et techniquement limitée.
- Aujourd’hui, on envoie uniquement la question et quelques paragraphes ciblés, choisis pour leur proximité sémantique avec la demande de l’utilisateur.
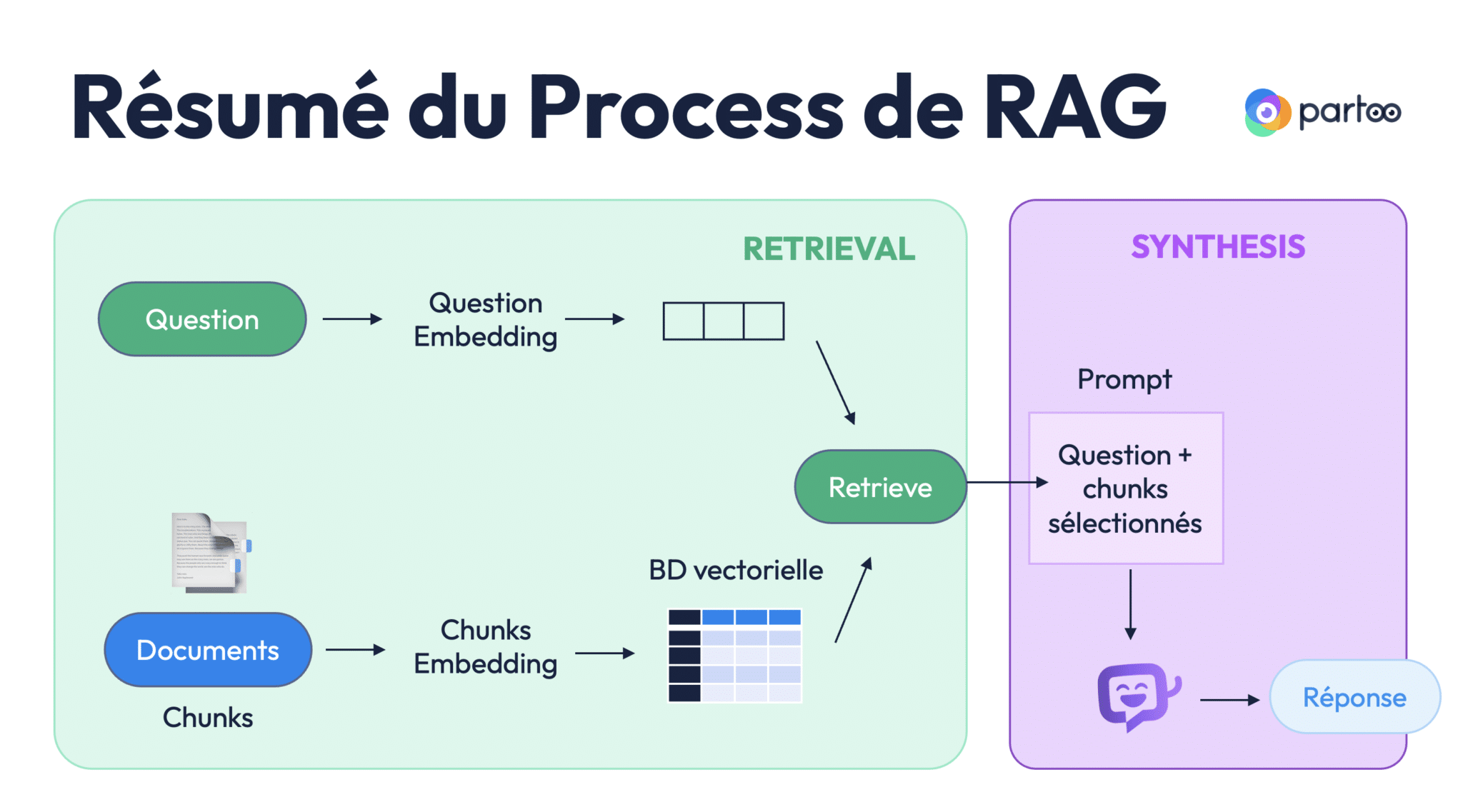
Schéma récapitulatif du pipeline RAG
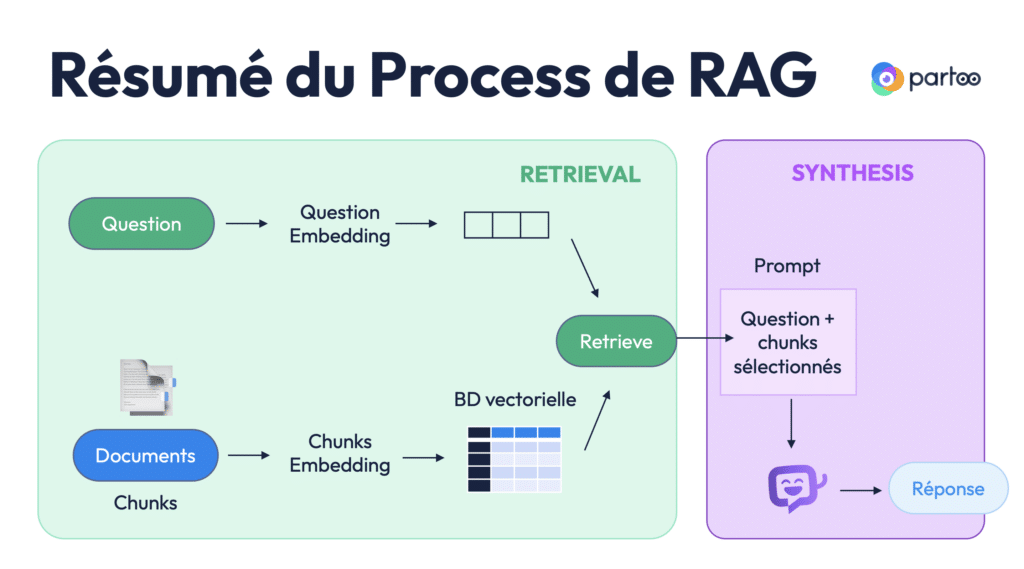
Pour résumer, voici les étapes d’un pipeline RAG appliqué à de la donnée non structurée :
- Question utilisateur → vectorisation via embedding → vecteur de question.
- Documents → découpés en chunks → vectorisés → base vectorielle.
- Comparaison des vecteurs → sélection des chunks les plus proches.
- Injection des chunks + question dans le prompt du LLM.
- Réponse générée par l’IA.